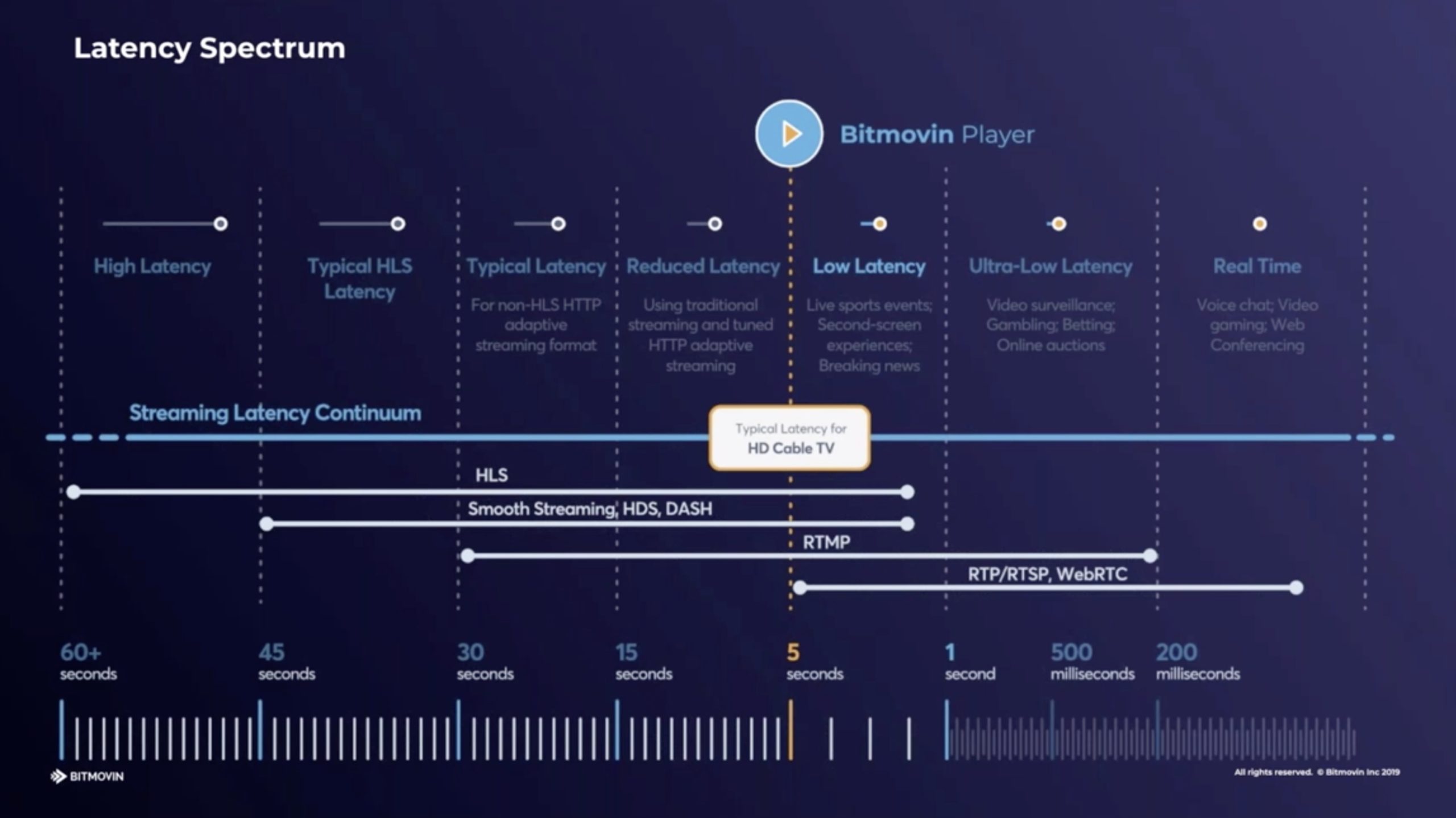
Apple’s LL-HLS protocol is the most recent technology offering to deliver low-latency streams of just 2 or 3 seconds to the viewer. Before that, CMAF which is built on MPEG DASH also enabled low latency streaming. This panel with Ateme, Akamai and THEOplayer asks how they both work, their differences and also maps out a way to deliver both at once covering the topic from the perspective of the encoder manufacturer, the CDN and the player client.
We start with ATEME’s Mickaël Raulet who outline’s CMAF starting with its inception in 2016 with Microsoft and Apple. CMAF was published in 2018 and most recently received detailed guidelines for low latency best practice in 2020 from the DASH Industry Forum. He outlines that the idea of CMAF is to build on DASH to find a single way of delivering both DASH and HLS using once set of media. THe idea here is to minimise hits on the cache as well as storage. Harnessing the ISO BMFF CMAF adds on the ability to break chunks in to fragments opening up the promise of low latency delivery.
Mickaël discusses the methods of getting hold of these short fragments. If you store the fragments separately, then you double your storage as 4 fragments make up a whole segment. So it’s better to have all the fragments written as a segment. We see that Byterange requests are the way forward whereby the client asks the server to start delivering a file from a certain number of bytes into the file. We can even request this ahead of time, using a preload hint, so that the server can push this data when it’s ready.
Next we hear from Akamai’s Will Law who examines how Apples LL-HLS protocol can work within the CDN to provide either CMAF for LL-HLS from the same media files. He uses the example of a 4-second segments with four second-long parts. A standard latency player would want to download the whole 4-second segment where as a LL-HLS player would want the parts. DASH, has similar requirements and so Will focusses on how to bring all of these requirements down into the mimum set of files needed which he calls a ‘common cache footprint’ using CMAF.
He shows how byterange requests work, how to structure them and explains that, to help with bandwidth estimation, the server will wait until the whole of the byterange is delivered before it sends any data thus allowing the client to download a wire speed. Moreover a single request can deliver the rest of the segments meaning 7 requests get collapsed into 1 or 2 requests which is an important saving for CDNs working at scale. It is possible to use longer GOPs for a 4-second video clip than for 1-second parts, but for this technique to work, it’s important to maintain the same structure within the large 4-second clip as in the 1-second parts.
THEOplayer’s Pieter-Jan Speelmans takes the floor next explaining his view from the player end of the chain. He discusses support for LL-HLS across different platforms such as Android, Android TV, Roku etc. and concludes that there is, perhaps surprisingly, fairly wide support for Apple’s LL-HLS protocol. Pieter-Jan spends some time building on Will’s discussion about reducing request numbers for browsers, CORS checking can increase cause extra requests to be needed when using Byterange requests. For implementing ABR, it’s important to understand how close you are to the available bandwidth. Pieter-Jan says that you shouldn’t only use the download time to determine throughput, but also metadata from the player to get as an exact estimate as possible. We also hear about dealing with subtitles which can need to be on screen longer than the duration of any of the parts or even of the segment length. These need to be adapted so that they are shown repeatedly and each chunk contains the correct information. This can lead to flashing on re-display so, as with many things in modern players, needs to be carefully and intentionally dealt with to ensure the correct user experience.
The last part of the video is a Q&A which covers:
Watch now!
Speakers
 |
Will Law Chief Architect, Edge Technology Group, Akamai |
 |
Mickaël Raulet CTO, ATEME |
 |
Pieter-Jan Speelmans CTO & Founder, THEOPlayer |