The codec arena is a lot more complex than before. Gone is the world of 5 years ago with AVC doing nearly everything. Whilst AVC is still a major force, we now have AV1 and VP9 being used globally with billions of uses a year, HEVC is not the force majeure it was once expected to be, but is now seeing significant use on iPhones and overall adoption continues to grow. And now, in 2020 we see three new codecs on the scene, VVC, EVC and LCEVC.
To help us make sense of this SMPTE has invited Walt Husak and Sean McCarthy to take us through what the current codecs are, what makes them different, how well they work, how to compare them and what the future roadmaps hold.
Sean starts by explaining which codecs are maintained by which bodies, with the IEC, ITU and MPEG being involved, not to mention the corporate codecs (VP8, and VP9 from Google) and the Chinese AVS series of codecs. Sean explains that these share major common elements and are each evolutions of each other. But why are all these codecs needed? Next, we see the use-cases that have brought these codecs into existence. Granted, AVC and HEVC entered the scene to reduce bitrate in an effort to make HD and UHD practical, respectively, but EVC and LC-EVC have different aims.
Sean gives a brief overview of the basics of encoding starting with partitioning the image, predicting parts of it, applying transformations, refining it (also known as applying ‘loop filters) and finishing with entropy codings. All of these blocks are briefly explained and exist in all the codecs covered in this talk. The evolutions which make the newer codecs better are therefore evolutions of each of these elements. For instance, explains Sean, splitting the image into different sections, known as partitioning, has become more sophisticated in recent codecs allowing for larger sections to be considered at once but, at the same time, smaller partitions created within each.
All codecs have profiles whereby the tools in use, or the complexity of their implementation, is standardised for certain types of video: 8-bit, 10-bit, HDR etc. This allows hardware implementers to understand the upper bounds of computation so they don’t end up over-provisioning hardware resources and increasing the cost. Sean looks at how VVC uses the same tools throughout all of its four profiles with only a few exceptions. Screen content sees two extra tools come for 4:2:2 formats and above. AV1 has the same tools throughout all the profiles but, deliberately, EVC doesn’t. Essential Video Coding has a royalty-free base layer that uses techniques that are not subject to any use payments. Using this layer gives you AVC-quality encoding, approximately. Using the main profile, however, gets you similar to HEVC encoding albeit with royalty payments.
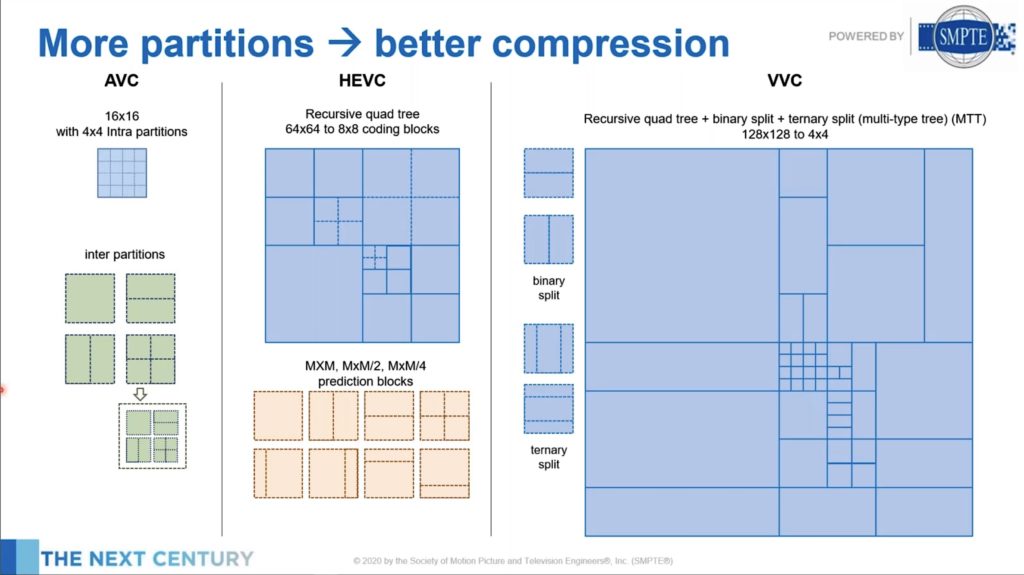
The next part of the talk examines two main reasons for the increase in compression over recent codec generation, block size and partitioning, before highlighting some new tools in VVC and AV1. Block size refers to the size of the blocks that an image is split up into for processing. By using a larger block, the algorithms can spot patterns more efficiently so the continued increase from 16×16 in AVC to 128×128 now in VVC drives an increase in computation but also in compression. Once you have your block, splitting it up following the features of the images is the next stage. Called partitioning, we see the number of ways that the codecs can mathematically split a block has grown significantly. VVC can also partition chroma separately to luma. VVC and AV1 also include 64 and 16 ways, respectively, to diagonally partition rather than the typical vertical and horizontal partitioning modes.
Screen content coding tools are increasingly important, pandemics aside, there has long been growth in the amount of computer-generated content being shared online whether that’s through esports, video conference screen sharing or elsewhere. Truth be told, HEVC has support for screen-content encoding but it’s not in the main profile so many implementations don’t support it. VVC not only evolves the screen-content tools, but it also makes it present as default. AV1, also, was designed to work well with screen content. Sean takes some time to look at the IBC tool, intra-block copy, which allows the encoder to relate parts of the current frame to other sections. Working at the prediction stage, with screen content that contains, for instance, lots of text, parts of that text will look similar and to a first approximation, one part of the image can be duplicated in another. This is similar to motion compensation where a macroblock is ‘copied’ to another frame in a different position, but all the work is done on the present frame for Intra BC. Palette mode is another screen content tool that allows the colour of a section of the image to be described as a palette of colours rather than using the full RGB value for each and every pixel.
Sean covers the scaled prediction between resolutions in VVC and super-resolution in AV1, VVC’s 360-degree video optimisations and luma mapping before handing over to Walt Husak who goes into more detail on how the newer codecs work, starting with LCEVC.
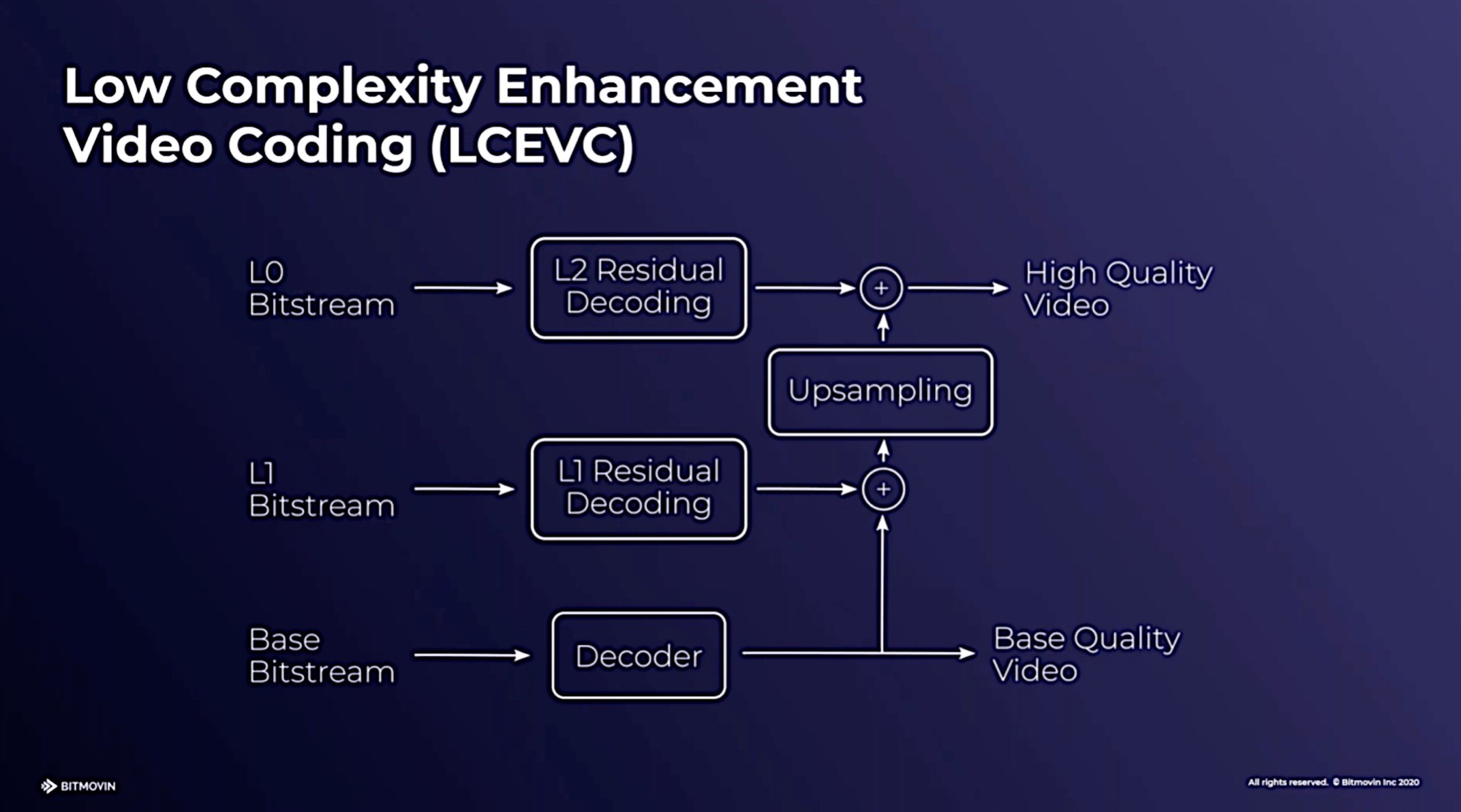
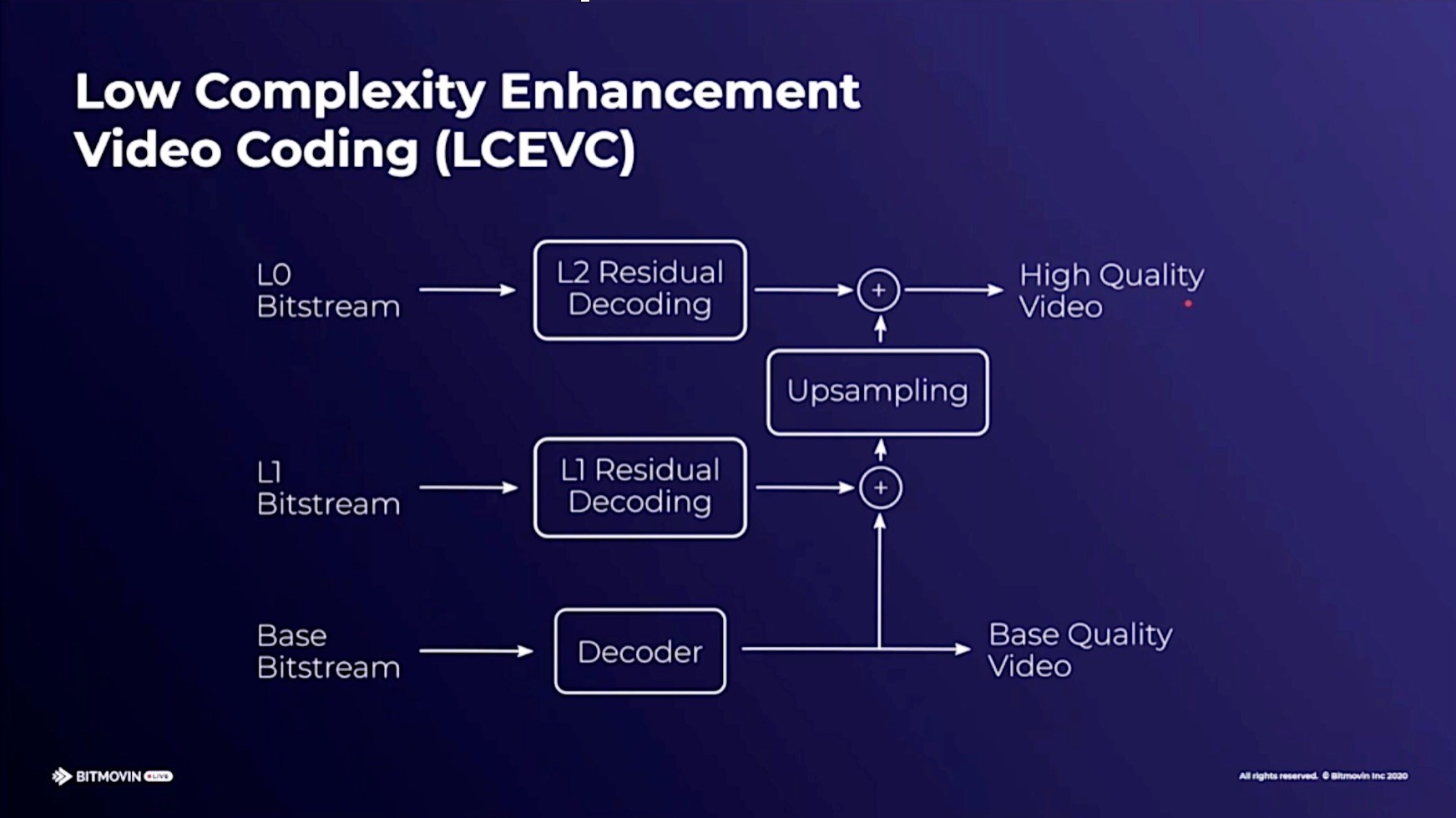
LCEVC is a codec that improves the performance of already-deployed codecs, typically used to enhance spatial resolution. If you wanted to encode HD, the codec would downsample the HD to an SD resolution and encode that with AVC, HEVC or another codec. At the same time, it would upsample that encoded video again and generate two correction layers that correct for artefacts and add sharpness. This information is added into the base codec and sent to the decoder. This can allow a software-only enhancement to a hardware deployment fully utilising the hardware which has already been deployed. Walt notes that the enhancement layers are much the same technology as has already been standardised by SMPTE as VC6 (ST 2117). LCEVC has been found to be computationally efficient allowing it to address markets such as embedded devices where hardware restrictions would otherwise prohibit the use of higher resolutions than for which it was originally designed. Very low bitrate performance is also very good.

Sean introduces us to his “Dos and Don’ts” of codec comparisons. The theme running through them is to take care that you are comparing like for like. Codecs can be set to run ‘fast’ or ‘slow’ each of which holds its own compromises in terms of encoding time and resulting quality. Similarly, there are some implementations that are made simply to implement the standard as rigorously as possible which is an invaluable tool when developing the codec or an implementation. Such a reference implementation for codec X, clearly, shouldn’t be compared to production implementations of a codec Y as the times are guaranteed to be very different and you will not learn anything from the process. Similarly, there are different tools that give codecs much more time to optimise known as single- and double-pass which shouldn’t be cross-compared.
The talk draws to a close with a look at codec performance. Sean shows a number of graphs showing how VVC performs against HEVC. Interestingly the metrics clearly show a 40% increase in efficiency of VVC over HEVC, but when seen in subjective tests, the ratings show a 50% improvement. VVC’s encoder is approximately 10x as complex as HEVC’s.
HEVC and AV1 perform similarly for the same bit rate. Overall, Sean says, AV1 is a little blurrier in regions of spatial detail and can have some temporal flickering. HEVC is more likely to have blocking and ringing artefacts. EVC’s main profile is up to 29% better than HEVC. LCEVC performs up to 8% better than AVC when using an AVC base layer and also slightly better than HEVC when using an HEVC based codec. Sean makes the point that the AVC has been continually updated since its initial release and is now on version 27, so it’s not strictly true to simply say it’s an ‘old’ codec. HEVC similarly is on version 7. Sean runs down part of the roadmap for AVC which leads on to the use of AI in codecs.
Finishing the video, Walt looks at the use of Deep Learning in codecs. Deep learning is also known as machine learning and referred to as AI (Artificial Intelligence). For most people, these terms are interchangeable and refer to the ability of a signal to be manipulated not by a fixed equation or algorithm (such as Lanczos scaling) but by a computer that has been trained through many millions of examples to recognise what looks ‘right’ and to replicate that effect in new scenarios.
Walt talks about JPEG’s AI learning research on still images who are aiming to complete an ‘end-to-end’ study of compression with AI tools. There’s also MPEG’s Deep Neural Network-based Video Coding which is looking at which tools within codecs can be replaced with AI. Also, recently we have seen the foundation of the MPAI (Moving Picture, Audio and Data Coding by Artificial Intelligence) organisation by Leonardo Chiariglione, an industry body devoted to the use of AI in compression. With all this activity, it’s clear that future advances in compression will be driven by the increasing use of these techniques.
The video ends with a Q&A session.
Watch now!
Find out more on SMPTE’s site
Speakers
 |
Sean McCarthy Director, Video Strategy and Standards, Dolby Laboratories |
 |
Walt Husak Director, Image Technologies, Dolby Laboratories |