

SMPTE’s ST-2110 standard can work on hardware or software, but its reliance on PTP, the Precision Time Protocol, makes full software support tricky. Why is this? Is this not just a question of more precise coding practices or changing programming language? There are times when PTP support for ST 2110 isn’t strictly needed and, indeed, the IPMX project is currently working on relaxing PTP requirements so that ST 2110 can be used in the ProAV market without ubiquitous PTP. But when you do need it on software deployed on a server, what are your options and what are the challenges?
This talk by Antoine Ténart looks at the pros and cons of using software vs hardware to create timestamps. First, however, Antoine looks at how PTP works. We’ve covered this before in a Cisco talk but Antoine points out that there are two methods that PTP can work, 1-step and 2-step. PTP synchronisation works by sending 2 messages from the grandmaster clock to the clock wanting to synchronise. There are also two messages sent back to the grandmaster. Keeping close track of when each of these messages was sent and received, and assuming the network delay is the same in both directions, you can work out how long it’s currently taking for timing messages to get to you. Once you’ve cracked the secret of how long messages get to you, you can accurately sync your clock to messages from the grandmaster which say ‘the time is currently …”
Without this exchange of messages, there’s no way to accurately synchronise your time with the PTP grandmaster within nanoseconds and you’d be left with NTP as your best option which can only keep accuracy within a few milliseconds. Some logs, transactions and media need much better accuracy than milliseconds. So with PTP relying on accurate timestamps, it’s important to find the best way to accurately stamp each message with its origin time.
Without hardware support, when the grandmaster sends its first message saying “This is the time”, a second message needs to be sent immediately afterwards saying “By the way, that last message actually left at a slightly different time:…” which is called the Follow-up Packet. Within broadcast, most equipment has hardware support and so can update the packet as it leaves the grandmaster with the actual time. When you can avoid the follow-up packet, this is known as a 1-step process.
As we covered in this the second talk from Cisco there is more than one type of clock: grandmaster, boundary and transparent. Antoine takes a moment to show how the boundary clock fits between end-devices and the grandmaster. For a deeper dive into PTP and its application to broadcast, watch Arista’s Gerard Philips in this IET Media talk.
Source: Antoine Ténart
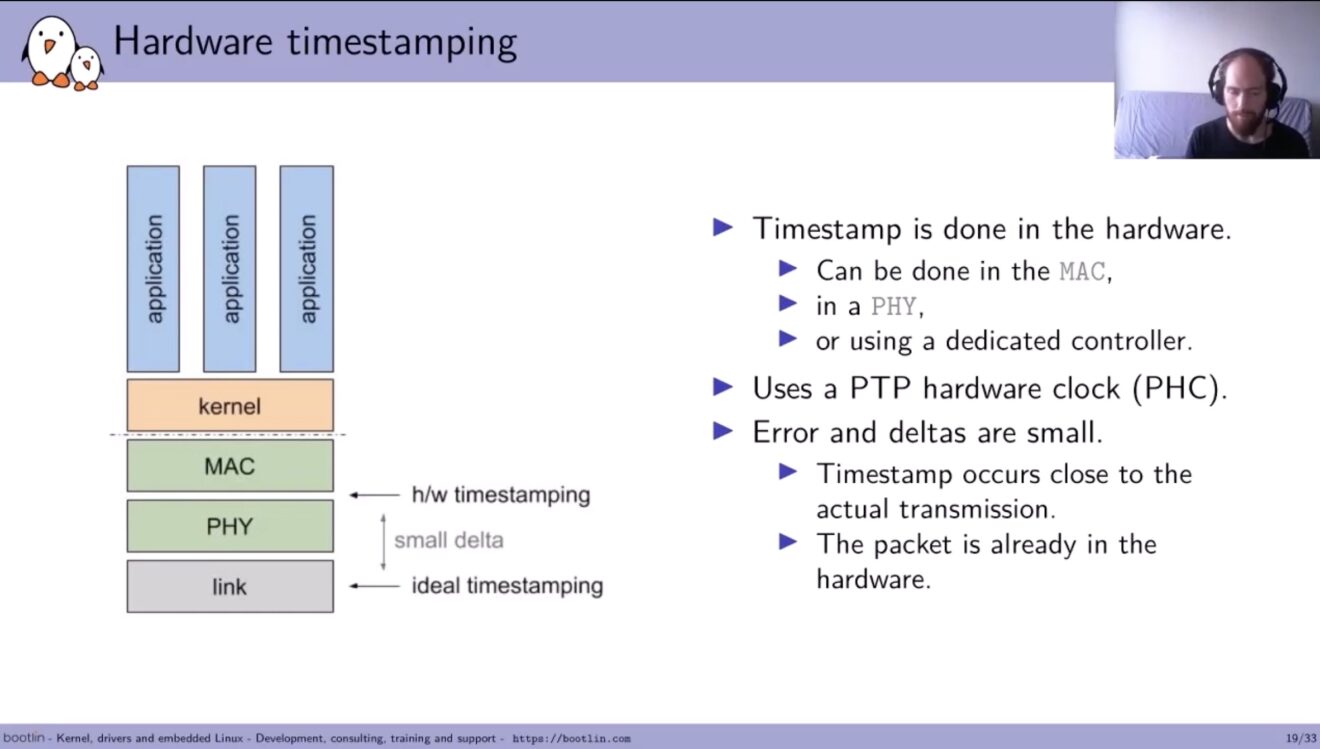
Antoine tackles both software and hardware timestamping next. Software, he shows is done in the application or the kernel using the system clock. The errors/deltas involved can be big with a long time passing before transmission. Not being certain when timestamps will occur leads to jitter in the timing signal.
Hardware insertion can be done in the Ethernet layer, in PHY or by a dedicated controller like the Mellanox X5 cards. Errors and deltas are small since the timestamp is inserted close to the actual transmission. In fact, the only delta is it crossing the PHY layer.
The video ends with Antoine discussing offloading, specific calls in the kernel such as SO_TIMESTAMPING and SO_TIMESTAMPTING_TX_HARDWARE as well as introducing us to some tools such as ptp4l, which is a PTP client and ptp2sys which updates the system clock to the ptp time.
Watch now!
Speaker
 |
Antoine Ténart Senior Software Engineer, Red Hat Former Linux Kernel Engineer, Bootlin |







