

Ioannis Katsavounidis from Facebook joins us to talk us through his work finding the best balance between computation and encoding. He explains how encoding has moved from real-time, hardware-based encoding in the late 80s and 1990s through to file encoding, chunk-based encoding and now shot-based encoding. Each of these stages has brought opportunities to speed up encoding, but there has always been a fundamental reason why encoding can’t simply be sped up by the advance of IT.
Moore’s law posits that every year, the number of transistors in chips doubles. Whilst this has continued to be true until recent years, transistors have always been a proxy for processing power. For many years now, the way to keep the computational ability of CPUs high has been not to increase clock-speed as it was twenty years ago, but to add cores to the chip. As each core acts as its own CPU, this gives the ability to execute code in parallel with a thread of code running separately on each core. Whilst 12-20 cores are typical for servers, there are CPUs which deliver up to 128 cores.
Ioannis explains why DCT-based codecs are resistant to multi-thread encoding by showing how some of the encoding decisions are based on the previously decoded video frame so the encoder needs to decode the video before it has the information it needs to make the next encode decisions. An example of this motion estimation where you need to understand what a macroblock looks like in order to detail if and how it can be moved to form part of the macroblock currently being encoded.
Source Ioannis Katsavounidis, Facebook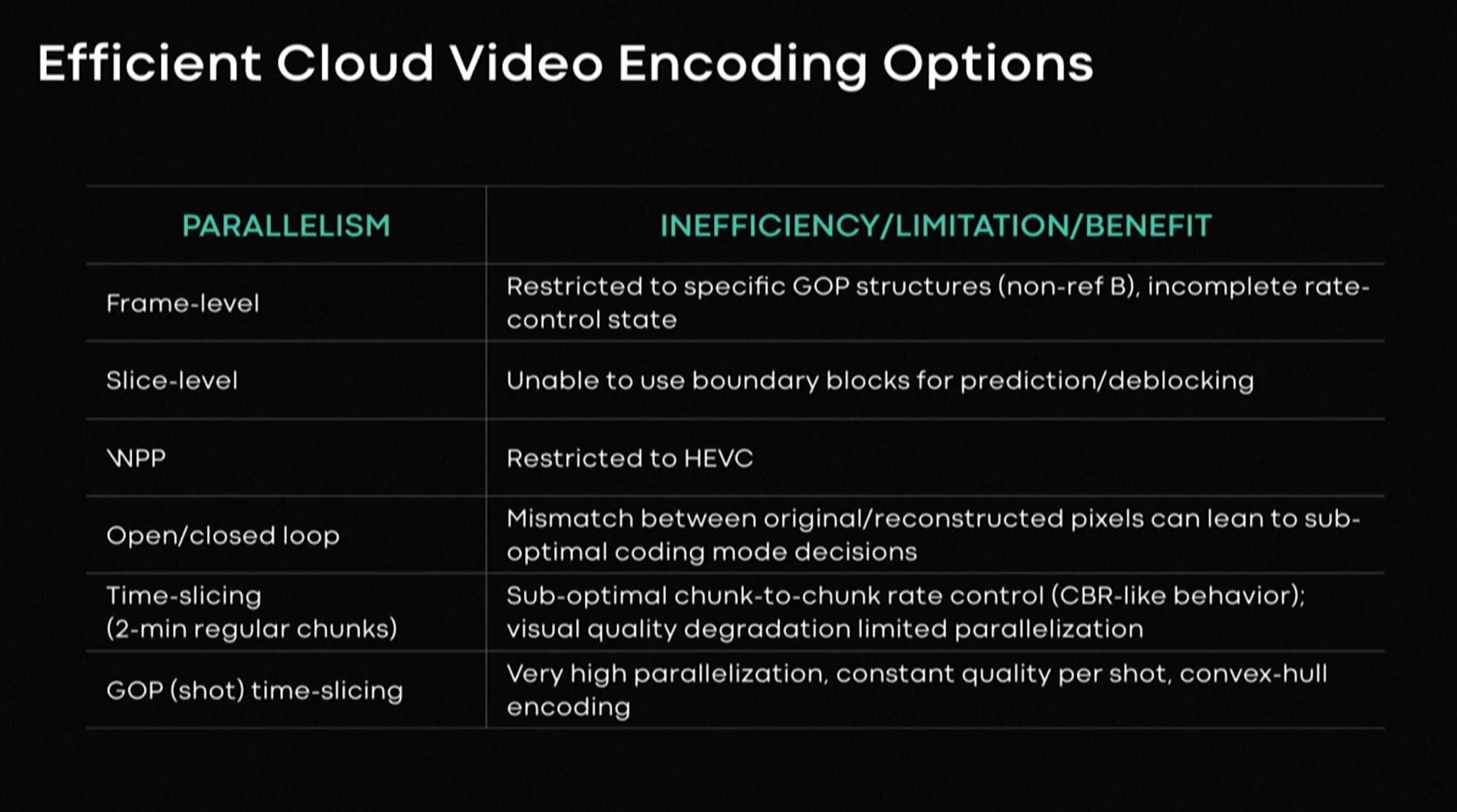
It turns out that some of the information you need to calculate can be found from the original video. Whilst this doesn’t provide full parallelisation, it does help in freeing some of the computation to be done in parallel thus reducing the length of time spent on the linear encoding stage. As the design of the codec itself is limited in its ability to be parallelised, the best way to speed up encoding has been to split up the original video and encode these, now separate, sections independently.
Speeding up video encoding has therefore focused on splitting up the video into different sections and encoding those in parallel rather than trying to parallelise the encoding itself due. Encoding each frame separately is one way to do this, but sacrifices encoding efficiency. Splitting each frame up into sections (tiles or slices) is another way, though this also sacrifices either quality or bitrate. The most successful encoding parallelisation has been chunked encoding. As streaming applications use chunks, typically around 2 seconds nowadays, there’s no reason not to just cut your video up into small sections and encode those separately; the whole of this video focuses on non-live video.
If there’s a shot change in the middle of your chunk, this is likely to look very bad since the motion estimation will fail to produce good results and there may not be enough bitrate budget to compensate. Therefore it’s best to drop in an IDR frame at the shot change or to actually change your video chunks to match shot changes. Simply encoding these chunks in parallel would speed up the encoding, however, it misses an opportunity to optimise quality vs bitrate.
Ioannis explains an experiment to determine the best operating point for chunks. He does that by reminding us that all encoders have certain ‘speed’ settings which control how much computation, and therefore time, is required for each encode. The ‘very fast’ setting in x264 will encode at the highest speed possible, but the quality will be worse or a certain bitrate compared to the ‘very slow’ setting. Ioannis’s experiment encoded each chunk at every speed setting for a variety of resolutions and bitrates. Each encode was then analysed for quality using PSNR, MS-SSIM and VMAF.
From Ioannis’ work, we can see how the bitrate setting affects both the encode time and the quality and we can observe that the slower speeds tend to have minimal quality advantages for the significant extra time involved in the encoding. Each curve has a steep part and a shallow section with the transition between known as the ‘convex hull’. Choosing a setting on the convex hull portion of the line is the optimal balance between quality and encoding time and is where, says Ioannis, most people should aim to operate.
The talk finishes with a summary of the conclusions which can be drawn from this work looking at the use of convex-hull which we’ve just discussed, the best type of parallel processing, whether oversubscription of CPU cores is helpful or not and an interesting observation that it’s often the metrics which put a significant burden on encoding rather than the video encoding itself, particularly for lower resolutions.
Watch now!
Speakers
 |
Ioannis Katsavounidis Research Scientist, |




