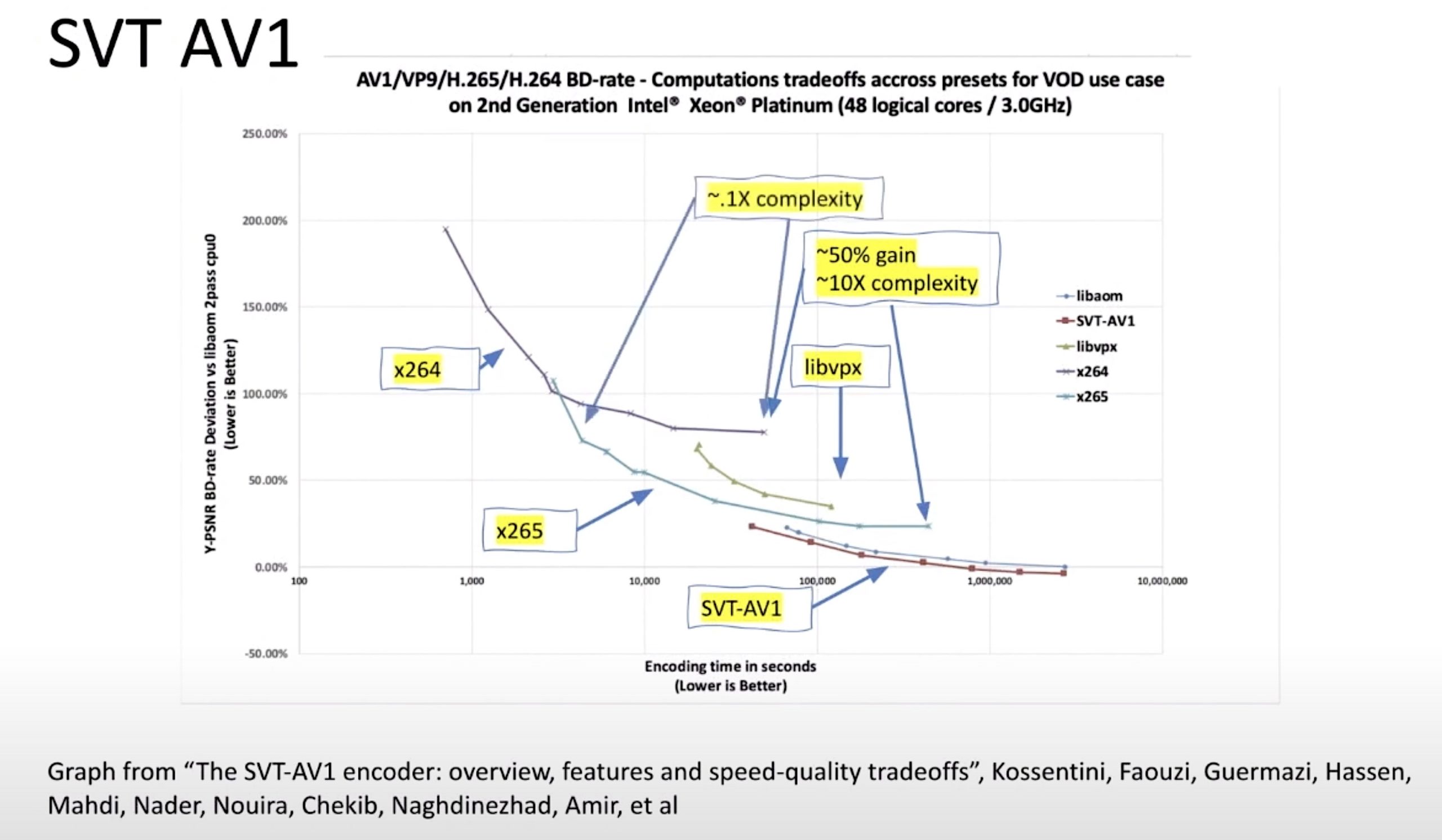
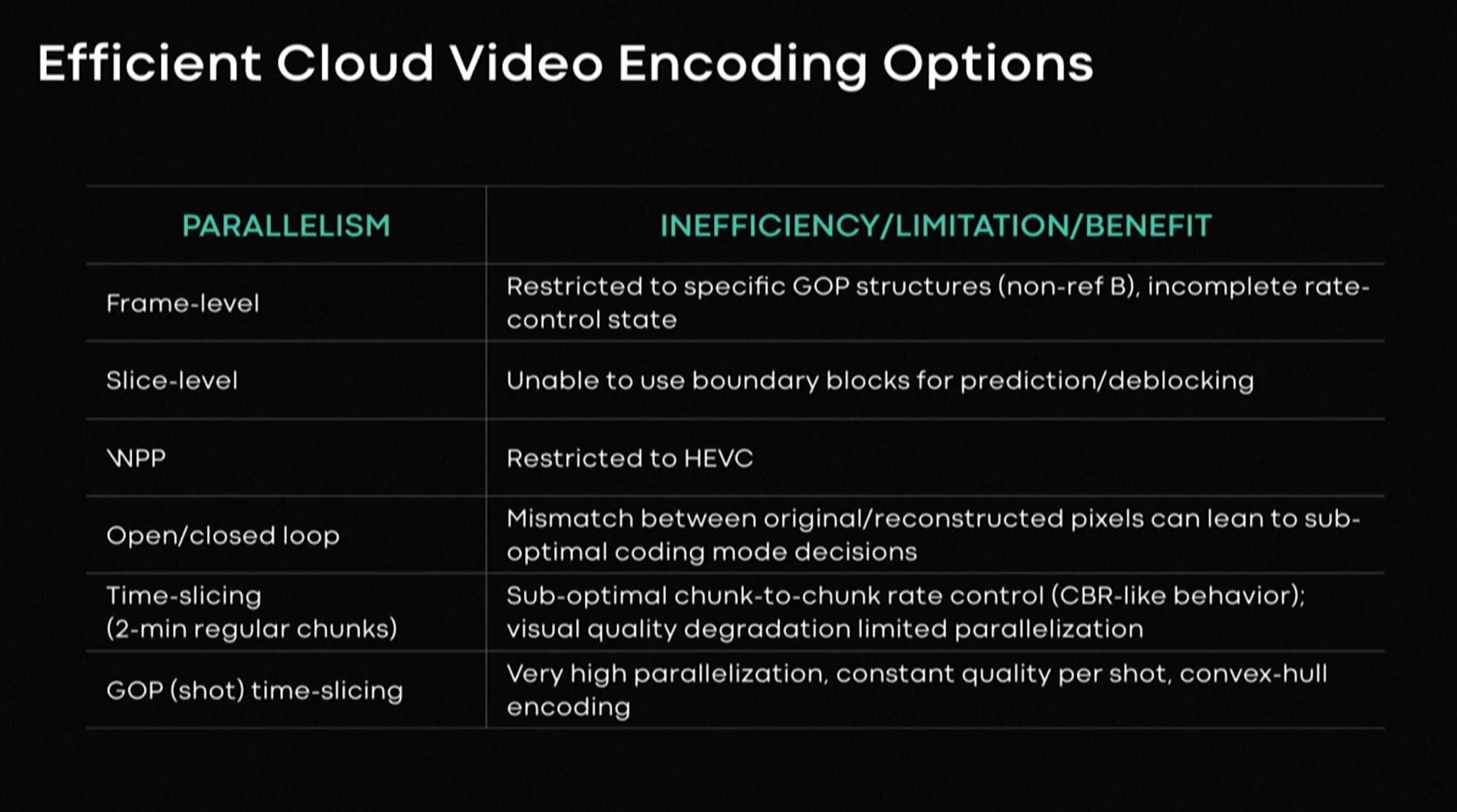
AI’s continues its march into streaming with this new approach to optimising encoder settings to keep down the bitrate and improve quality for viewers. By its more appropriate name, ‘machine learning’, computers learn how to characterise video to avoid hundreds of encodes whilst determining the best way to encode video assets.
Daniel Silhavy from Fraunhofer FOKUS takes the stand at Mile High Video 2020 to detail the latest technique in per-title and per-scene encoding. Daniel starts by outlining the problem with fixed ABR which is that efficiencies are gained by being flexible both with resolution and with bitrate.
Netflix were the best-known pioneers of the per-title encoding idea where, for each different video asset, many, many encodes are done to determine the best overall bitrate to choose. This is great because it will provide for animation-based files to be treated differently than action films or sports. Efficiency is gained.
However, per-title delivers an average benefit. There are still parts of the video which are simple and could see reduced bitrate and arts where complexity isn’t accounted for. When bitrate is higher than necessary to achieve a certain VMAF score, Danel calls this ‘wasted quality’. This means bitrate was used making the quality better than we needed it to be. Whilst better quality sounds like a boon, it’s not always possible for it to be seen, hence having a target VMAF at a lower level.
Naturally, rather than varying the resolution mix and bitrate for each file, it would be better to do it for each scene. Working this way, variations in complexity can be quickly accounted for. This can also be done without machine learning, but more encodes are needed. The rest of the talk looks at using machine learning to take a short-cut through some of that complexity.
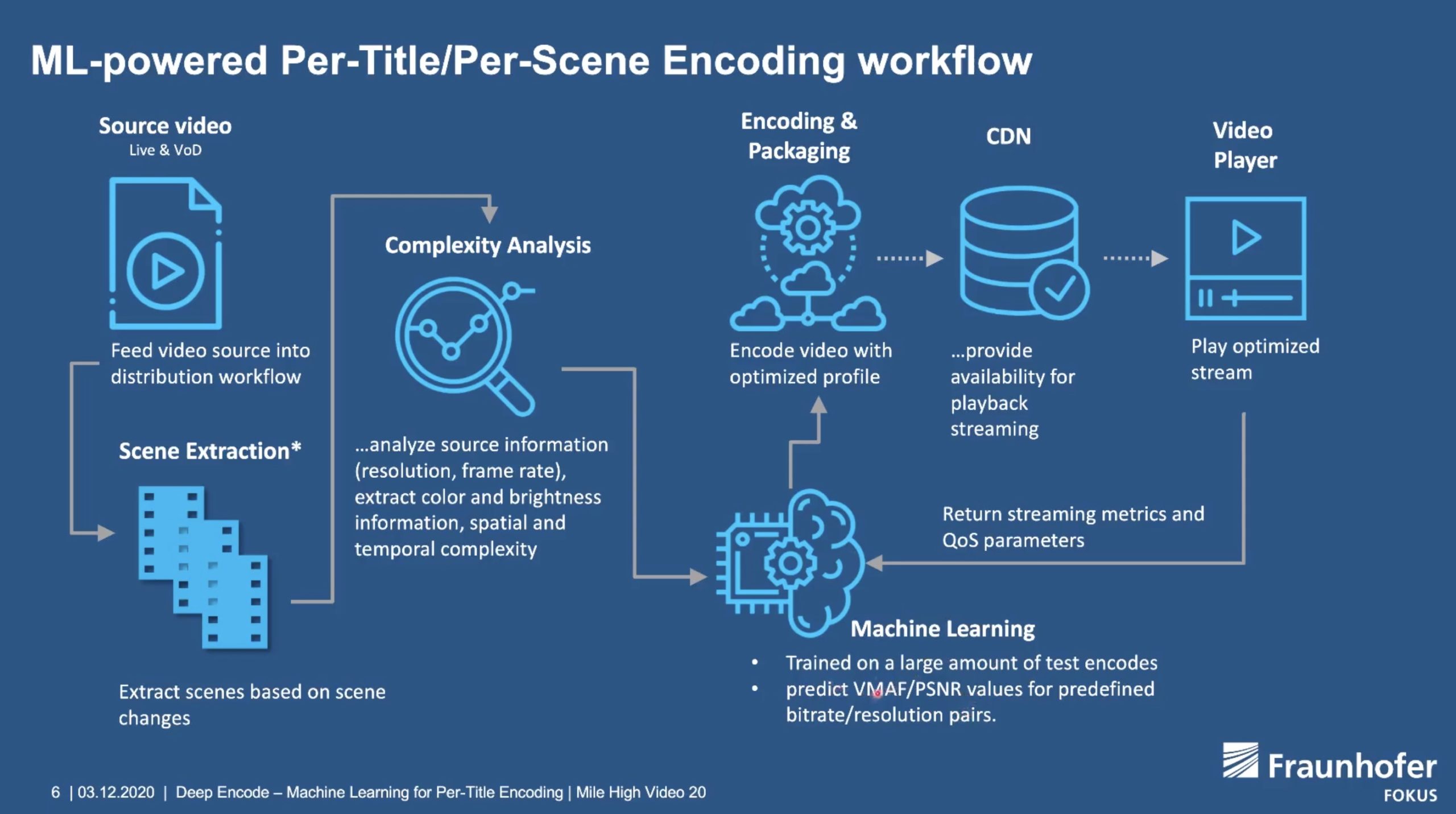
The standard workflow is to perform a complexity analysis on the video, working out a VMAF score at various bitrate and resolution combinations. This produces a ‘Convex hull estimation’ allowing determination of the best parameters which then feed in to the production encoding stage.
Machine learning can replace the section which predicts the best bitrate-resolution pairs. Fed with some details on complexity, it can avoid multiple encodes and deliver a list of parameters to the encoding stage. Moreover, it can also receive feedback from the player allowing further optimisation of this prediction module.
Daniel shows a demo of this working where we see that the end result has fewer rungs on the ABS ladder, a lower-resolution top rung and fewer resolutions in general, some repeated at different bitrates. This is in common with the findings of Facebook which we covered last week who found that if they removed their ‘one bitrate per resolution rule’ they could improve viewers’ experience. In total, for an example Fraunhofer received from a customer, they saw a 53% reduction in storage needed.
Watch now!
Download the slides
Speakers
 |
Daniel Silhavy Scientist & Project Manager, Fraunhofer FOKUS |