VVC was finalised in mid-2020 after five years of work. AVC’s still going strong and is on its 26th version, so it’s clear there’s still plenty of work ahead for those involved in VVC. Heavily involved in AVC, HEVC and now VVC is the Fraunhofer Heinrich Hertz Institute (HHI) who are patent holders in all three and for VVC they are, for the first time, developing a free, open-source encoder and decoder for the standard.
In this video from OTTVerse.com, Editor Krishna Rao speaks to Benjamin Bross and Adam Więckowsk both from Fraunhofer HHI. Benjamin has previously been featured on The Broadcast Knowledge talking at Mile High Video about VVC which would be a great video to check out if you’re not familiar with this new codec given before its release.
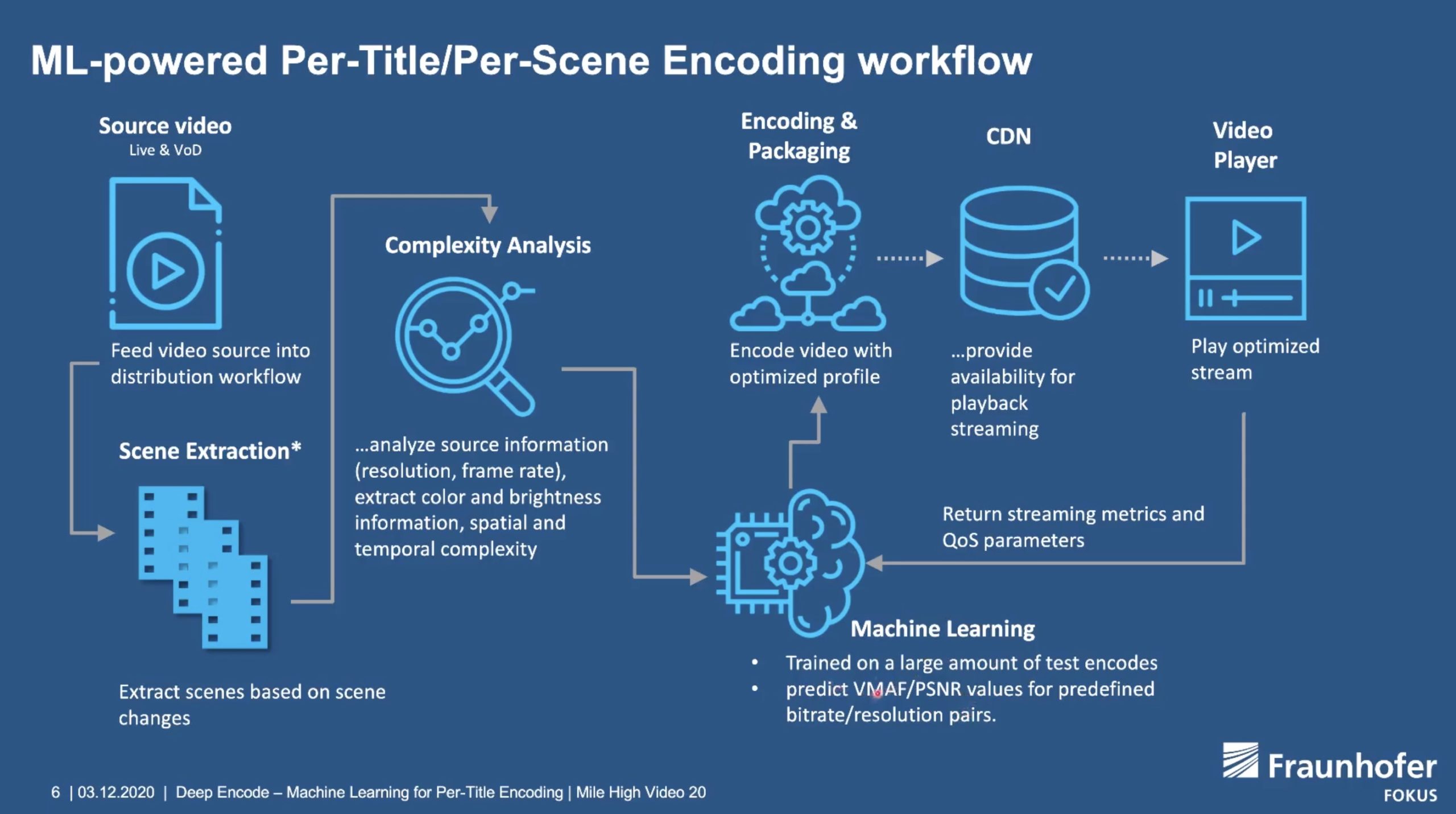
They start by discussing how the institute is supported by the German government, money received from its patents and similar work as well as the companies who they carry out research for. One benefit of government involvement is that all the papers they produce are made free to access. Their funding model allows them the ability to research problems very deeply which has a number of benefits. Benjamin points out that their research into CABAC which is a very efficient, but complex entropy encoding technique. In fact, at the time they supported introducing it into AVC, which remember is 19 years old, it was very hard to find equipment that would use it and certainly no computers would. Fast forward to today and phones, computers and pretty much all encoders are able to take advantage of this technique to keep bitrates down so that ability to look ahead is beneficial now. Secondly, giving an example in VVC, Benjamin explains they looked at using machine learning to help optimise one of the tools. This was shown to be too difficult to implement but could be replaced by matrix multiplication which and was implemented this way. This matrix multiplication, he emphasises, wouldn’t have been able to be developed without having gone into the depths of this complex machine learning.
Krishna suggests there must be a lot of ‘push back’ from chip manufacturers, which Benjamin acknowledges though, he says people are just doing their jobs. It’s vitally important, he continues, for chip manufacturers to keep chip costs down or nothing would actually end up in real products. Whilst he says discussions can get quite heated, the point of the international standardisation process is to get the input at the beginning from all the industries so that the outcome is an efficient, implementable standard. Only by achieving that does everyone benefit for years to come.e
The conversation then moves on to the open source initiative developing VVenC and VVdeC. These are separate from the reference implementation VTM although the reference software has been used as the base for development. Adam and Benjamin explain that the idea of creating these free implementations is to create a standard software which any company can take to use in their own product. Reference implementations are not optimised for speed, unlike VVenC and VVdeC. Fraunhofer is expecting people to take this software and adapt it for, say 360-degree video, to suit their product. This is similar to x264 and x265 which are open source implementations of AVC and HEVC. Public participation is welcomed and has already been seen within the Github project.
Adam talks through a slide showing how newer versions of VVenC have increased speed and bitrate with more versions on their way. They talk about how some VVC features can’t really be seen from normal RD plots giving the example of open vs closed GOP encoding. Open GOP encoding can’t be used for ABR streaming, but with VVC that’s now a possibility and whilst it’s early days for anyone having put the new type of keyframes through their paces which enable this function, they expect to start seeing good results.
The conversation then moves on to encoding complexity and the potential to use video pre-processing to help the encoder. Benjamin points out that whilst there is an encode increase to get to the latest low bitrates, to get to the best HEVC can achieve, the encoding is actually quicker. Looking to the future, he says that some encoding tools scale linearly and some exponentially. He hopes to use machine learning to understand the video and help narrow down the ‘search space’ for certain tools as it’s the search space that is growing exponentially. If you can narrow that search significantly, using these techniques becomes practical. Lastly, they say the hope is to get VVenC and VVdeC into FFmpeg at which point a whole suite of powerful pre- and post- filters become available to everyone.
Watch now!
Full transcript of the video
Speakers
 |
Benjamin Bross
Head of Video Coding Systems Group,
Fraunhofer Heinrich Hertz Institute (HHI)
|
 |
Adam Więckowski
Research Assistant
Fraunhofer HHI
|
 |
Moderator: Krishna Rao Vijayanagar
Editor,
OTTVerse.com
|