HEVC continues to gain adoption thanks to its bitrate savings over AVC (H.264), though much stands in the balance this year as AV1 continues to gain momentum and MPEG’s VVC is released. Both of which promise greater compression. Compression, however, is a compromise between encoding complexity (computation), quality and speed. HEVC stands on the shoulders of AVC and this video explains the techniques it uses to be better.
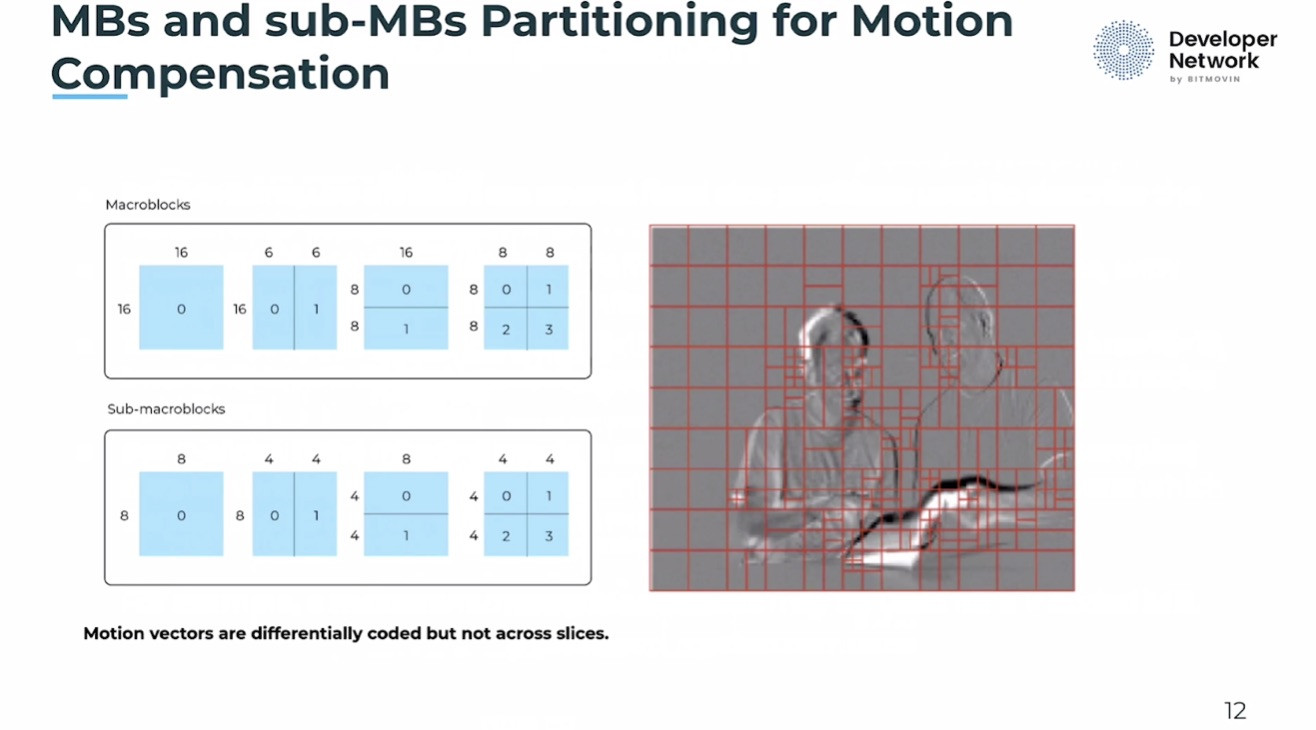
Christian Timmerer, co-founder of Bitmovin, builds on his previous video about AVC as he details the tools and capabilities of HEVC (all known as H.265). He summarises the performance of HEVC as providing twice as much compression for the same video quality (or getting better quality for a higher number of bits). Whilst it’s decoder requirements have gone up by 50%, it provides better parallelisation opportunities. Amongst the features that create this are variable block-size motion compensation, improved interpolation method and more directions for spatial prediction. Most of the improvements are specifically an expansion of the abilities laid out in AVC. For instance, making size or direction variable or providing more options.
After outlining some of the details behind the new capabilities, we look at the performance improvements of some HEVC implementations over AVC implementations showing up to a 65% improvement of bitrate averaging out at around 50%. Christian finishes by looking at the newer codecs coming out soon such as VVC, LCEVC
Watch now!
Speakers
 |
Christian Timmerer CIO & Cofounder, Bitmovin Associate Professor, Universität Klagenfurt |