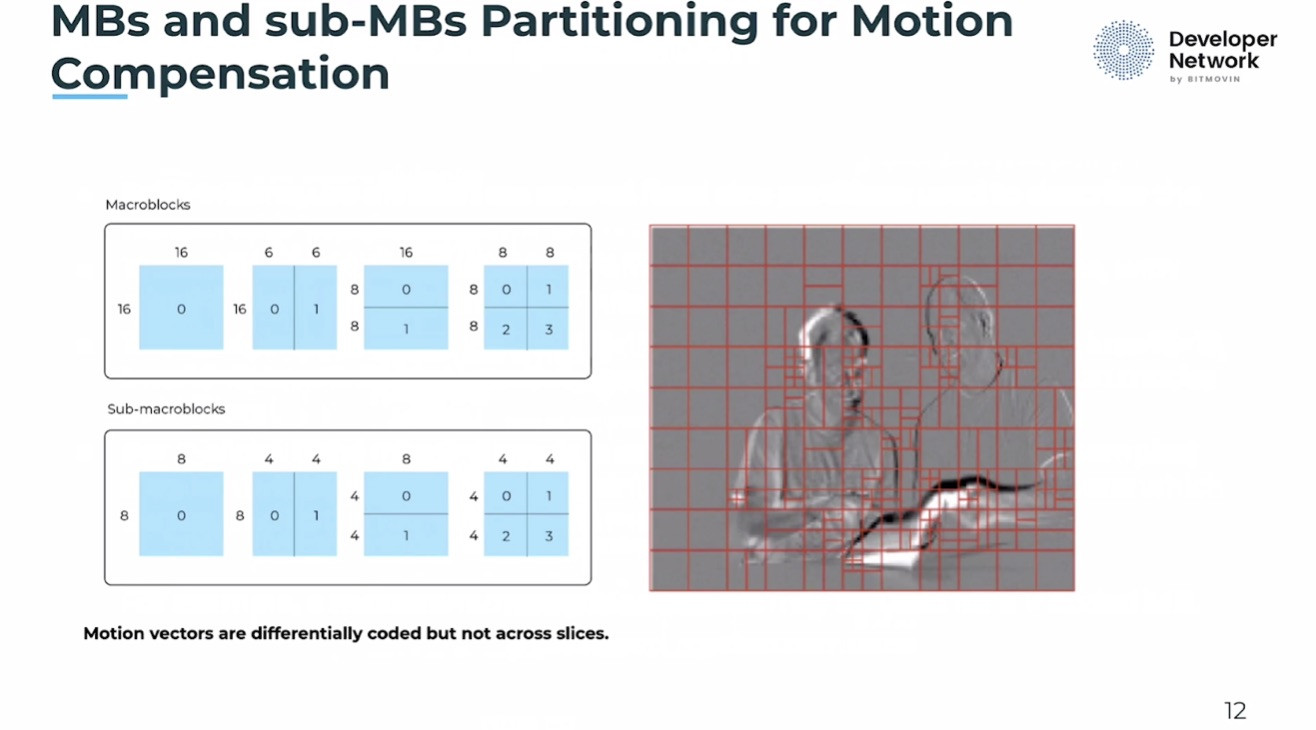
There are many ways of achieving a hybrid of OTT-delivered and broadcast-delivered content, but they are not necessarily interoperable. DVB aims to solve the interoperability issue, along with the problem of service discovery with DVB-I. This specification was developed to bring linear TV over the internet up to the standard of traditional broadcast in terms of both video quality and user experience.
DVB-I supports any device with a suitable internet connection and media player, including TV sets, smartphones, tablets and media streaming devices. The medium itself can still be satellite, cable or DTT, but services are encapsulated in IP. Where both broadband and broadcast connections are available, devices can present an integrated list of services and content, combining both streamed and broadcast services.
DVB-I standard relies on three components developed separately within DVB: the low latency operation, multicast streaming and advanced service discovery. In this webinar, Rufael Mekuria from Unified Streaming focuses on low latency distributed workflow for encoding and packaging.
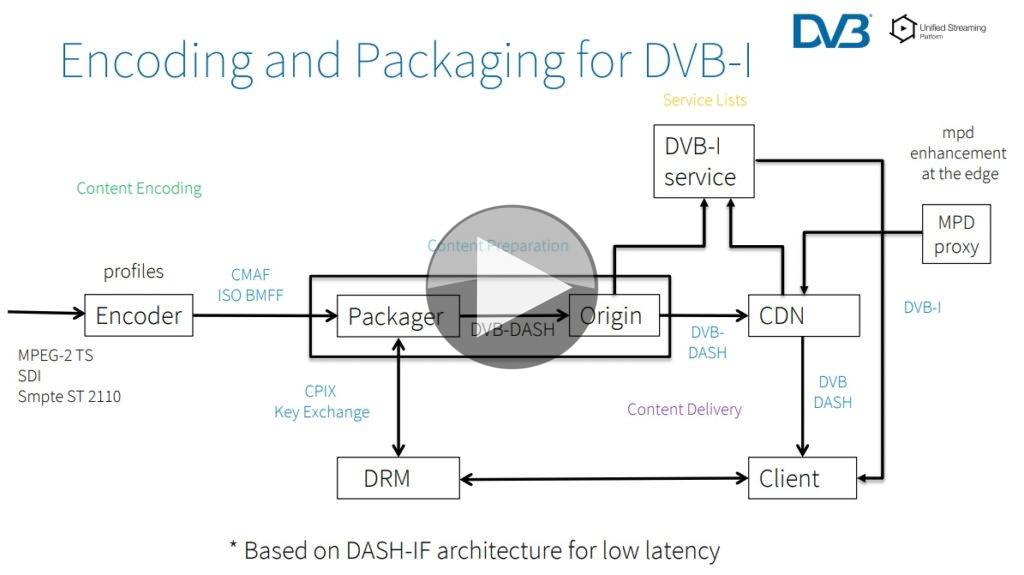
The process starts with an ABR (adaptive bit rate) encoder responsible for producing streams with multiple bit rates and clear segmentation – this allows clients to automatically choose the best video quality depending on available bandwidth. Next step is packaging where streaming manifests are added and content encryption is applied, then data is distributed through origin servers and CDNs.
Rufael explains that low latency mode is based on an enhancement to the DVB-DASH streaming specification known as DVB Bluebook A168. This incorporates the chunked transfer encoding of the MPEG CMAF (Common Media Application Format), developed to enable co-existence between the two principle flavors of adaptive bit rate streaming: HLS and DASH. Chunked transfer encoding is a compromise between segment size and encoding efficiency (shorter segments make it harder for encoders to work efficiently). The encoder splits the segments into groups of frames none of which requires a frame from a later group to enable decoding. The DASH packager then puts each group of frames into a CMAF chunk and pushes it to the CDN. DVB claims this approach can cut end-to-end stream latency from a typical 20-30 seconds down to 3-4 seconds.
The other topics covered are: encryption (exhanging key parameters using CPIX), content insertion, metadata, supplemental descriptors, TTML subitles and MPD proxy.
Speaker
 |
Rufael Mekuria Head of Research & Standardization Unified Streaming |