
The benefits of IP sound great, but many are held back with real-life concerns: Can we afford it? Can we plug the training gap? and how do we even do it? This video looks at the latter; how do you deploy a network good enough for uncompressed video, audio and metadata? The network needs to deal with a large number of flows, many of which are high bandwidth. If you’re putting it to air, you need reliability and redundancy. You need to distribute PTP timing, control and maintain it.
Gerard Philips from Arista talks to IET Media about the choices you need to make when designing your network. Gerard starts by reminding us of the benefits of moving to IP, the most tangible of which is the switching density possible. SDI routers can use a whole rack to switch over one thousand sources, but with IP Gerard says you can achieve a 4000-square router within just 7U. With increasingly complicated workflows and with the increasing scale of some broadcasters, this density is a major motivating factor in the move. Doubling down on the density message, Gerard then looks at the difference in connectivity available comparing SDI cables which have signal per cable, to 400Gb links which can carry 65 UHD signals per link.
Audio is always ahead of video when it comes to IP transitions so there are many established audio-over-IP protocols, many of which work at Layer 2 over the network stack. Using Layer 2 has great benefits because there is no routing which means that discovering everything on the network is as simple as broadcasting a question and waiting for answers. Discovery is very simple and is one reason for the ‘plug and play’ ease of NDI, being a layer 2 protocol, it can use mDNS or similar to query the network and display sources and destinations available within seconds. Layer 3-based protocols don’t have this luxury as some resources can be on a separate network which won’t receive a discovery request that’s simply broadcast on the local network.
Gerard examines the benefits of layer 2 and explains how IGMP multicast works detailing the need for an IGMP querier to be in one location and receiving all the traffic. This is a limiting factor in scaling a network, particularly with high-bandwidth flows. Layer 3, we hear, is the solution to this scaling problem bringing with it more control of the size of ‘failure domains’ – how much of your network breaks if there’s a problem.
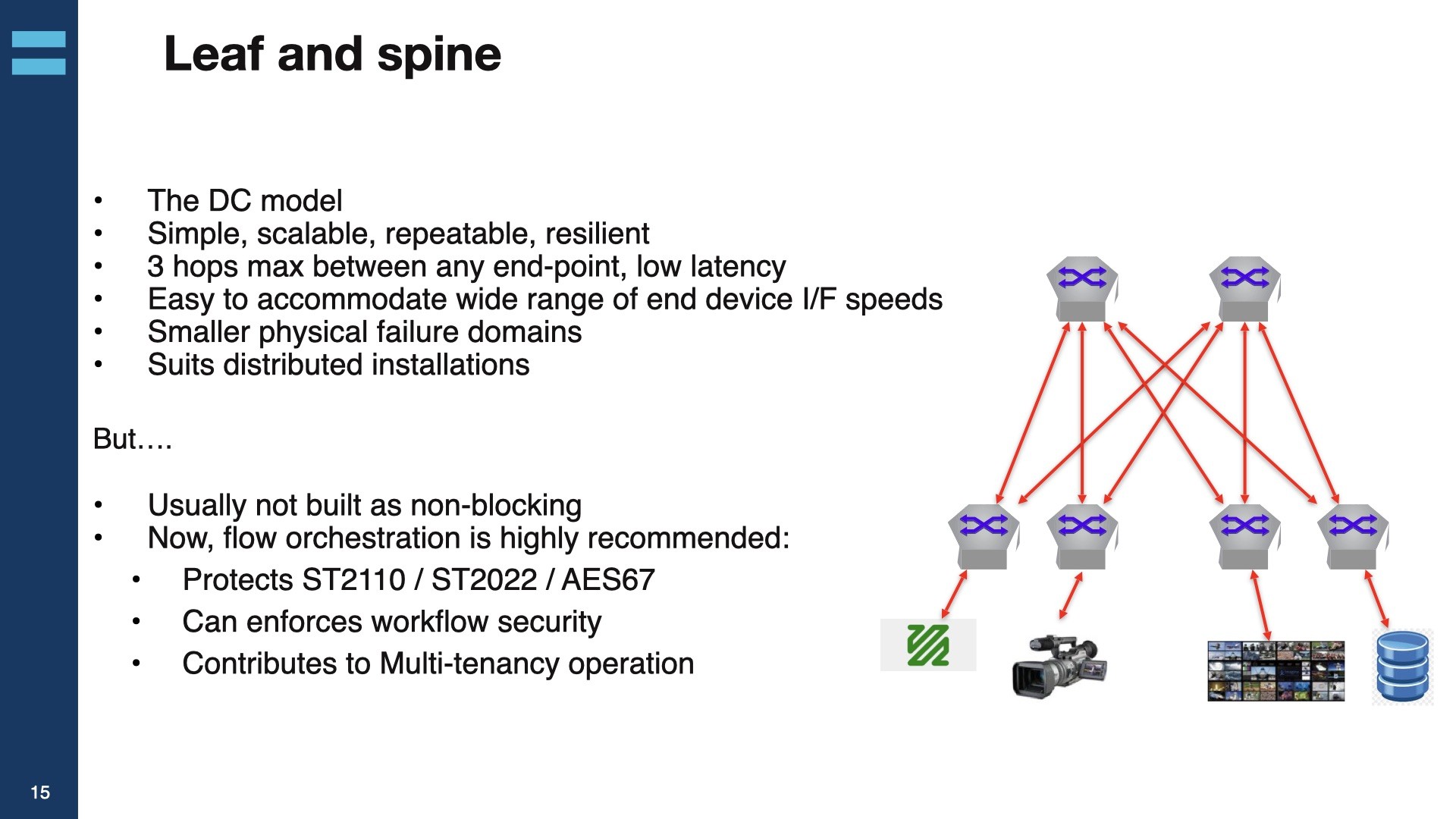
The next section of the video gets down to the meat of network design and explains the 3 main types of architecture: Monolithic, Hub and spoke and leaf and spoke. Gerard takes time to discuss the validity of all these architectures before discussing coloured networks. Two identical networks dubbed ‘Red’ and ‘Blue’ are often used to provide redundancy in SMPTE ST 2110, and similar uncompressed, networks with the idea that the source generates two identical streams and feeds them over these two identical networks. The receiver receives both streams and uses SMPTE ST 2022-7 to seamlessly deal with packet loss. Gerard then introduces ‘purple’ networks, ones where all switch infrastructure is in the same network and the network orchestrator ensures that each of the two essence flows from the source takes a separate route through the infrastructure. This means that for each flow there is a ‘red’ and a ‘blue’ route, but overall each switch is carrying a mixture of ‘red’ and ‘blue’ traffic.
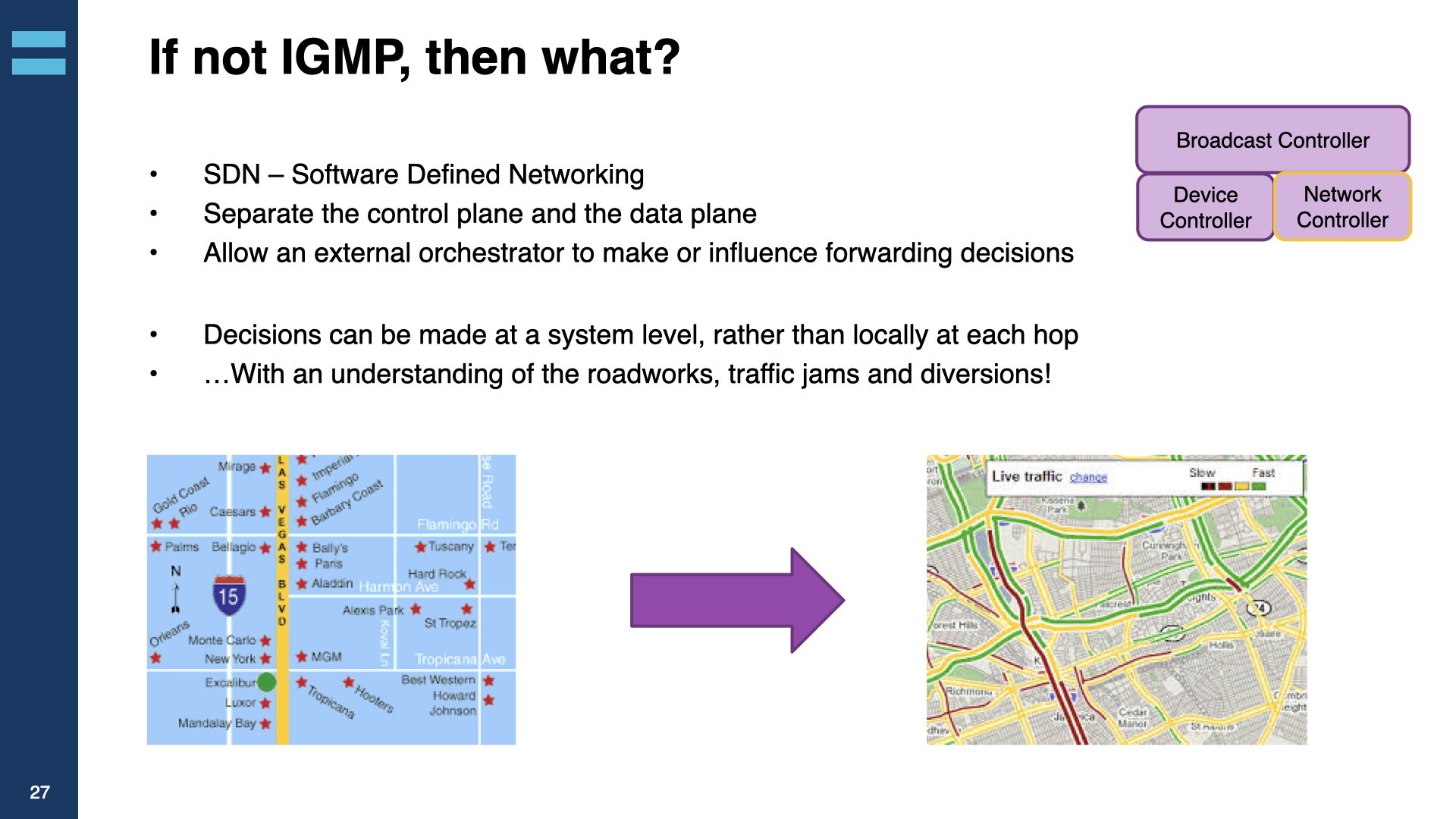
The beauty of using IGMP/PIM for managing traffic over your networks is that the network itself decides how the flows move over the infrastructure. This makes for a low-footprint, simple installation. However, without the ability to take into account individual link capacity, the capacity of the network in general, bitrate of individual flows and understanding the overall topology, there is very control over where your traffic is which makes maintenance and fault-finding hard and, more generally, what’s the right decision for one small part of the network is not necessarily the right decision for the flow or for the network as a whole. Gerard explains how Software-Defined Networking (SDN) address this and give absolute control over the path your flows take.
Lastly, Gerard looks at PTP, the Precision Time Protocol. 2110 relies on having the PTP in the flow, in the essence allowing flows of separate audio and video to have good lip-sync and to avoid phase errors when audio is mixed together (where PTP has been used for some time). We see different architectures which include two grandmaster clocks (GMs), discuss whether boundary clocks (BCs) or transparent clocks (TCs) are the way to go and examine the little security that is available to stop rogue end-points taking charge and becoming grandmaster themselves.
Watch now!
Speaker

|
Gerard Phillips
Systems Engineer,
Arista
|










