AV1’s royalty-free status continues to be very appealing, but in raw compression is it losing ground now to the newer codecs such as VVC? EVC has also introduced a royalty-free model which could also detract from AV1’s appeal and certainly is an improvement over HEVC’s patent debacle. We have very much moved into an ecosystem of patents rather than the MPEG2/AVC ‘monoculture’ of the 90s within broadcast. What better way to get a feel for the codecs but to put them to the test?
Dan Grois from Comcast has been looking at the new codecs VVC and EVC against AV1 and HEVC. VVC and EVC were both released last year and join LCEVC as the three most recent video codecs from MPEG (VVC was a collaboration between MPEG and ITU). In the same way, HEVC is known as H.265, VVC can be called H.266 and it draws its heritage from the HEVC too. EVC, on the other hand, is a new beast whose roots are absolutely shared with much of MPEG’s previous DCT-based codecs, but uniquely it has a mode that is totally royalty-free. Moreover, its high-performant mode which does include patented technology can be configured to exclude any individual patents that you don’t wish to use thus adding some confidence that businesses remain in control of their liabilities.
Dan starts by outlining the main features of the four codecs discussing their partitioning methods and prediction capabilities which range from inter-picture, intra-picture and predicting chroma from the luma picture. Some of these techniques have been tackled in previous talks such as this one, also from Mile High Video and this EVC overview and, finally, this excellent deep dive from SMPTE in to all of the codecs discussed today plus LCEVC.
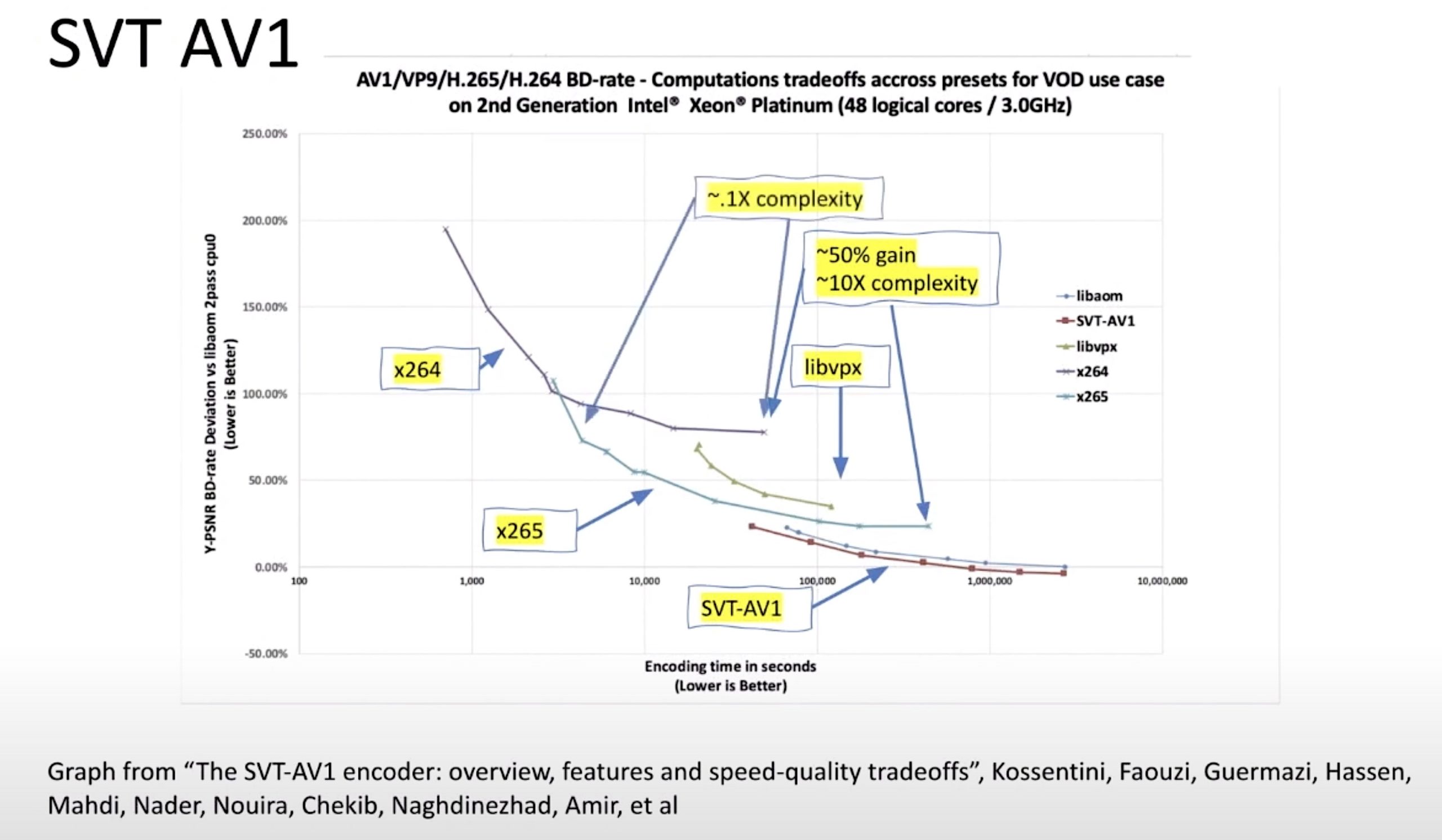
Dan explains the testing he did which was based on the reference encoder models. These are encoders that implement all of the features of a codec but are not necessarily optimised for speed like a real-world implementation would be. Part of the work delivering real-world implementations is using sophisticated optimisations to get the maths done quickly and some is choosing which parts of the standard to implement. A reference encoder doesn’t skimp on implementation complexity, and there is seldom much time to optimise speed. However, they are well known and can be used to benchmark codecs against each other. AV1 was tested in two configurations since
AV1 needs special treatment in this comparison. Dan explains that AV1 doesn’t have the same approach to GOPs as MPEG so it’s well known that fixing its QP will make it inefficient, however, this is what’s necessary for a fair comparison so, in addition to this, it’s also run in VBR mode which allows it to use its GOP structure to the full such as AV1’s invisible frames which carry data which can be referenced by other frames but which are never actually displayed.
The videos tested range from 4K 10bit down to low resolution 8 bit. As expected VVC outperforms all other codecs. Against HEVC, it’s around 40% better though carrying with it a factor of 10 increase in encoding complexity. Note that these objective metrics tend to underrepresent subjective metrics by 5-10%. EVC consistently achieved 25 to 30% improvements over HEVC with only 4.5x the encoder complexity. As expected AV1’s fixed QP mode underperformed and increased data rate on anything which wasn’t UHD material but when run in VBR mode managed 20% over HEVC with only a 3x increase in complexity.
Watch now!
Speaker
 |
Dan Grois Principal Researcher, Comcast |