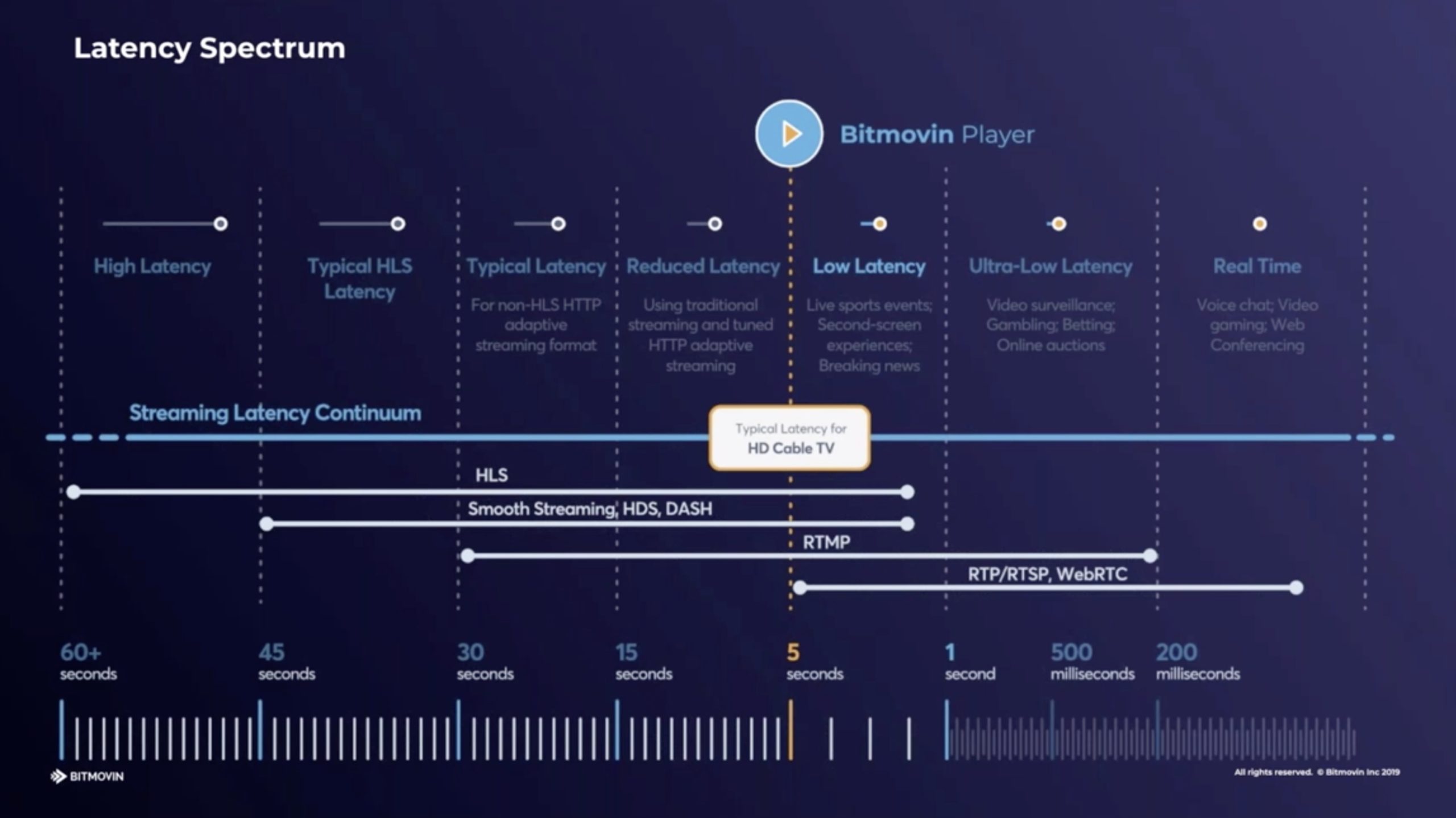
The streaming industry is on an ever-evolving quest to reduce latency to bring it in line with, or beat linear broadcasts and to allow business models such as gaming to flourish. When streaming started, latency of a minute or more was not uncommon and whilst there are some simple ways to improve that, getting down to the latency of digital TV, approximately 5 seconds, is not without challenges. Whilst the target of 5 seconds works for many use cases, it’s still not enough for auctions, gambling or ‘gamification’ which need sub-second latency.
In this panel, Jason Thielbaut explores how to reduce latency with Casey Charvet from Gigcasters, Rob Roskin from CenturyLink and Haivision VP Engineering, Marc Cymontkowski. This wide-ranging discussion covers CDN caching, QUIC and HTTP/3, encoder settings, segmented Vs. non-segmented streaming, ingest and distribution protocols.
Key to the discussion is differentiating the ingest protocol from the distribution protocol. Often, just getting the content into the cloud quickly is enough to bring the latency into the customer’s budget. Marc from Haivision explains how SRT achieves low-latency contribution. SRT allows unreliable networks like the Internet to be used for reliable, encrypted video contribution. Created by Haivision and now an Open Source technology with an IETF draft spec, the alliance of SRT users continues to grow as the technology continues to develop and add features. SRT is a ‘re-request’ technology meaning it achieves its reliability by re-requesting from the encoder any data it missed. This is in contrast to TCP/IP which acknowledges every single packet of data and is sent missing data when acknowledgements aren’t received. Doing it the SRT, way really makes the protocol much more efficient and able to cope with real-time media. SRT can also encrypt all traffic which, when sending over the internet, is extremely important even if you’re not sending live-sports. In this video, Marc makes the point that SRT also recovers the timing of the stream so that the data comes out the SRT pipe in the same ‘shape’ as it went in. Particularly with VBR encoding, your decoder needs to receive the same peaks and troughs as the encoder created to save it having to buffer the input as much. All this included, SRT manages to deliver a transport latency of around 2.5 times the round trip time.
Haivision are members of RIST which is a similar technology to SRT. Marc explains that RIST is approaching the problem from a standards perspective; taking IETF RFCs and applying them to RTP. SRT took a more pragmatic way forward by creating a binary which implemented the features and by making this open source for interoperability.
The video finishes with a Q&A covering HTTP Header compression, recommended size of HLS chunks, peer-to-peer streaming and latency requirements for VoD.
Running the live streaming for an event can be fraught, so preparation needs to be the number one priority. In this talk, Robert Reinhardt, a highly experienced streaming consultant takes us through choosing encoders, finding out what the client wanted, helping the client understand what needs to be done, choosing software and ensuring the event stays on air.
This is a wide-ranging and very valuable talk for anyone who’s going to be involved with a live streaming event. In this article, I’ll highlight 3 of the big topics nestled in with the continuous stream of tips and nuances that Rob unearths.
System Architecture. Reliability is usually a big deal for live streaming and this needs to be a consideration not only in the streaming infrastructure in the cloud, but in contribution and the video equipment itself. No one wants to have a failed stream due to a failed camera, so have two. Can you afford a hardware switcher/vision mixer? Rob prefers hardware units in terms of reliability (no random OS reboots), but he acknowledges this is not always practical or possible. Audio, too needs to be remembered and catered for. It’s always better to have black vision and hear the programme than to have silent video. Getting your streams from the event into the cloud can also be done resiliently either by having dual streams into a Wowza server or similar or having some other switching in the cloud. Rob spends some time discussing
whether to use AVC or HEVC, plus the encoder manufacturers that can help.
Discovery and Budget Setting. This is the most important part of Rob’s talk. Finding out what your customer wants to achieve in a structured, well recorded way is vital in order to ensure you meet their expectations and that their expectations are realistic. This discovery process can also be used as a way to take the customer through the options available and decisions that need to be made. For many clients, this discovery process then starts to happen on both sides. Once the client is fully aware of what they need, this can directly feed into the budget setting.
Discovery is more than just helping get the budget right and ensure the client has thought of all aspects of the event, it’s also vital in drawing a boundary around your work and allows you to document your touchpoints who will be providing you things like video, slides and connectivity. Rob suggests using a survey to get this information and offers, as an example, the survey he uses with clients. This part of the talk finishes with Rob highlighting costs that you may incur that you need to ensure are included. Rob has also written up his advice.
Setup and Testing. Much of the final part of the presentation is well understood by people who have done events before and is summarised as ‘test and test again’. But it’s always helpful to have this reiterated and, in this case, from the streaming angle. Rob goes through a long list of what to determine ahead of the event, what to test on-site ahead of the event and again what to test just before the event.
KPIs are under the microscope as Milan’s Video Tech meet up fights against the pandemic by having its second event online and focused on measuring, and therefore improving, streaming services.
Looking at ‘Data-Driven Business Decision Making‘, Federico Preli, kicks off the event looking at how to harness user data to improve the user experience. He explains this using Netflix’s House of Cards as an example. Netflix commissioned 2 seasons of House of Cards based not on a pilot, but on data they already have. They knew the British version had been a hit on the platform, they could see that the people who enjoyed that, also watched other films from Kevin Spacey or David Fincher (the director of House of Cards). As such, this large body of data showed that, though success was not guaranteed, there was good cause to expect people to be receptive to this new programme.
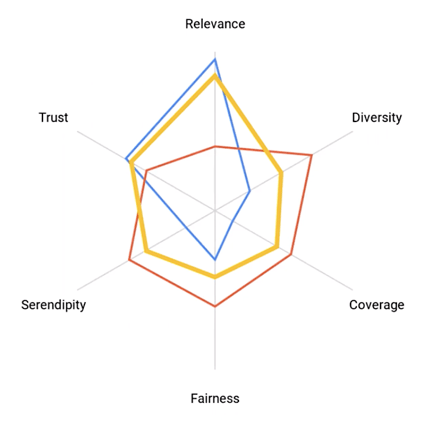
Federico goes on to explain how to balance recommendations based upon user data. A balance is necessary, he explains, to avoid a bubble around a viewer where the same things keep on getting recommended and not to exaggerate someone’s interests at the detriment of nuance and not representing the less prominent predilections. He outlines the 5 parts of a balanced recommendations experience: Serendipity, diversity, coverage, fairness & trust. Balancing these equally will provide a rounded experience. Finally, Federico discusses how some platforms may choose to under invest in some of these due to the nature of their platforms. Relevance, for instance, may be less important for an ultra-niche platform where everything has relevance.
‘Performance Video KPIs at the Edge‘ is the topic of Luca Moglia‘s talk. A media solutions engineer from Akamai, he looks at how to derive more KPI information from logs at the edge. Whilst much data comes from a client-side KPI, data directly reported by the video player itself to the service. Client-side information is vital as only the client knows on which button you clicked, for instance and how long you spent in certain parts of the GUI. But in terms of video playback, there is a lot to be understood by looking at the edge, the part of the CDN which is closest to the client.
One aspect that client-side reporting doesn’t cover is use of the platform by clients which aren’t fully supported meaning they report back less information. Alternatively, for some services, it may be possible to access them with clients which don’t report at all. Depending on how reporting is done, this could be blocked by ad blockers or DNS rules. As such, this is an important gap which can be largely filled by analysis of CDN logs. This allows you to enhance the data analysis done elsewhere and validate it.
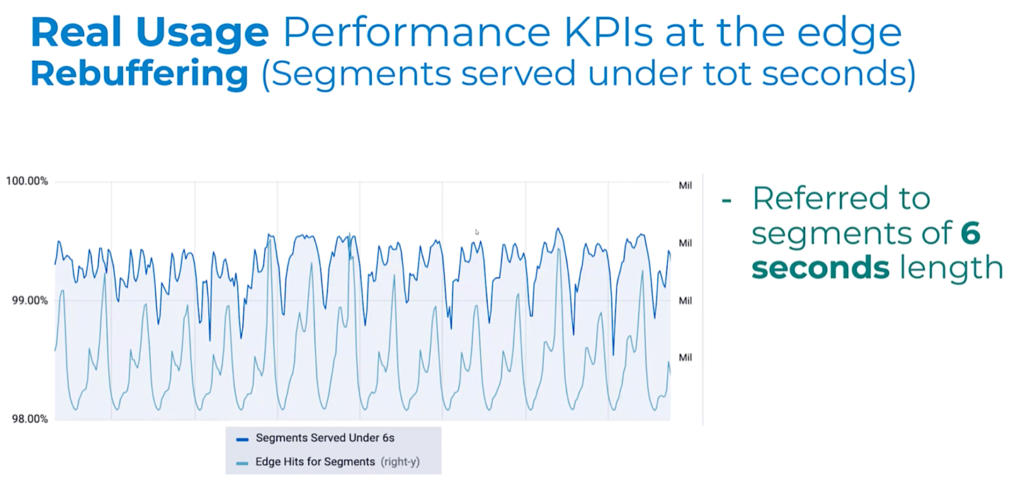
Luca gives examples of KPIs that can be measured or inferred from the edge, such as ‘hand-waving latency’ which can be understood from the edge-to-origin latency and time to manifest. He also shows an example graph analysing the number of segments served at the edge within the segment duration time. This helps indicate how many streams weren’t rebuffering. Overall, Luca concludes, analysing data from the edge helps track improvements, gives you better visibility on consumer/global events and allows you to enhance the performance of the platform.
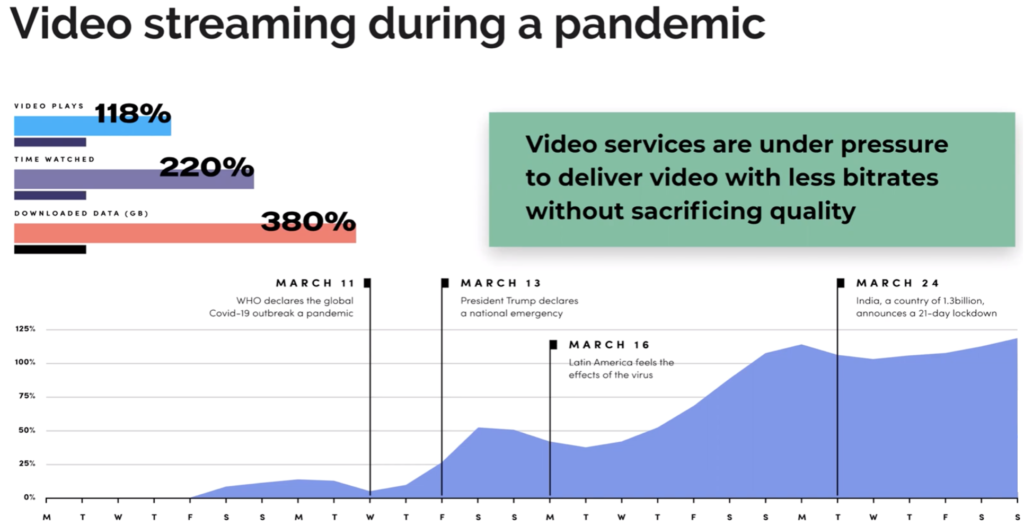
Bitmovin’s Andrea Fassina covers ‘Client KPIs – Five Analytics Metrics That Matter‘ which he summarises at the beginning of his talk ahead of explaining each individually. ‘Impressions & Total Hours Watched’ is first. This metric has really shown its importance as the SARS-CoV-2 pandemic has rolled around the globe. Understanding how much more people are watching is important in understanding how your platform is reacting. After all, if a platform is struggling this could be for many reasons that are correlated with, but not because of, more hours streamed. For instance, in boxing matches, it’s often the payment system which struggles before the streaming does.
Video startup time is next. Andrea explains the statistics of lost viewers as your time-to-play increases. You can look at startup time across each device and see where the low-hanging fruit for improvements and prioritise your work. This metric can be extended to ad playing and DRM load time which need to be brought into the overall equation.
Third is Video Bitrate Heatmap which allows you to see which type of chunks are most used and, similarly, which rungs on your ABR ladder aren’t needed (or could be improved.) The fourth KPI discussed is Error Types and Codes. Analysing codes generated can give you early warning to issues and allow you to understand whether you suffer more problems than the industry average (6.6%) but also proactively talk to connectivity providers to reduce problems. Lastly, Andrea explains how Rebuffering percentage helps understand where there are gaps in your service in terms of devices/apps which are particularly struggling.
Source: Andrea Fassina, Bitmovin
‘Video Quality Metrics‘ rounds off the session as Fabio Sonnati tackles the tricky problem of how to know what quality of video each viewer is seeing. Given that the publisher has each and every chunk and can view them, many would think this would mean you could see exactly what each stream would look like. But a streaming service can only see what each chunk looks like on their device in their environment. When you view a chunk encoded at 1080i on an underpowered SD device, what does the user actually see and would they have been better receiving a lower resolution, lower bitrate chunk instead?
In order to understand video quality, Fabio briefly explains some objective metrics such as VMAD, SSIM and PSNR. He then discusses the way that Sky Italia have chosen to create their own metric by combining metrics, subjective feedback and model training. The motivation to do this, to tailor your metric to the unique issues that your platform has to contend with. This metric, called SynthEYE, has been expanded to be able to run without a reference – i.e. it doesn’t require the source as well as the encoded version. Fabio shows results of how well SynthEYE Absolute predicts VMAF and MOS scores. He concludes by saying that using an absolute metric is useful because it gives you the ability to analyse chunk-by-chunk and then match that up with resolution and other analytics data to better understand the performance of the platform.
There are a number of techniques for achieving low-latency streaming. This talk is one of the few which introduces them in easy to understand ways and then puts them in context briefly showing the manifests or javascript examples of how these would be seen in the wild. Whilst there are plenty of companies who don’t need low-latency streaming, for many it’s a key part of their offering or it’s part of the business model itself. Knowing the techniques in play is to better understand internet streaming in general.
Jameson Steiner from Bitmovin starts by explaining why there is a motivation to cut the latency. One big motivation, aside from the standard live sports examples, is user-generated content like on Twitch where it’s very clear to the streamer, and quite off-putting, when there is large amounts of delay. Whilst delay can be adapted to, the more there is the less interaction is possible. In this situation, it’s the ‘handwaving’ latency that comes in to play. You want the hand on the screen to wave pretty much at the same time as your hand waves in front of the camera. Jameson places different types of distribution on a chart showing latency and we see that low-latency of 5 seconds or less will not only match traditional TV broadcasts, but also work well for live streamers.
Naturally, to fix a problem you need to understand the problem, so Jameson breaks down the legacy methods of delivery to show why the latency exists. The issue comes down to how video is split into sections, say 6 seconds, so that the player downloads a section at a time, reassembles and plays them. Looking from the player’s perspective, if the network suddenly broke or reduced its throughput, it makes sense to have several chunks in reserve. Having three 6-second chunks, a sensible precaution, makes you 18 seconds behind the curve from the off.
Clearly reducing the segement size is a winner in this scenario. Three 3 second segments will give you just 9 seconds latency; why not go to 1 second? Well encoding inefficiency is one reason. If you reduce the amount of time a temporal codec has of a video, its efficiency will drop and bitrate will increase to maintain quality. Jameson explains the other knock-on effects such as CDN inefficiencies and network requests. The standardised way to avoid these problems is to use CMAF (Common Media Application Format) which is based on MPEG DASH and ISO BMFF. CMAF, and DASH in general, has the benefit of coming from a standards body whose aim was to remove vendor lock-in that may be felt with HLS and was certainly felt with RTMP. Check out MPEG’s short white paper on the topic (zipped .docx file)
CMAF uses chunked transfer meaning that as the encoder writes the data to the disk, the web server sends it to the client. This is different to the default where a file is only sent after it’s been completely written. This has the effect of the not having to wait up to 6 seconds to a 6-second chunk to start being sent; the download time also needs to be counted. Rather, almost as soon as the chunk has been finished by the encoder, it’s arrived at the destination. This is a feature of HTTP 1.1 and after so is not new, but it still needs to be enabled and considered as part of the delivery.
CMAF goes beyond simple HTTP 1.1 chunked transfer which is a technique used in low-latency HLS, covered later, by creating extra structure within the 6-second segment (until now, called a chunk in this article). This extra structure allows the segment to be downloaded in smaller chunks decoupling the segment length from the player latency. Chunked transfer does cause a notable problem however which has not yet been conclusively solved. Jameson explains how traditionally each large segment typically arrives faster than realtime. By measuring how fast it arrives, given the player knows the duration, it can estimate the bandwidth available at that time on the network. With chunked transfer, as we saw, we are receiving data as it’s being created. By definition, we are now getting it in realtime so there is no opportunity to receive it any quicker. The bandwidth estimation element, as shown the presentation, is used to work out if the player needs to go down or could go up to another stream at a different bitrate – part of standard ABR. So the catastrophe here is the going down in latency has hampered our ability to switch bitrates and whilst the viewer can see the video close to real-time, who’s to say if they are seeing it at the best quality?
Low-Latency HLS/DASH is a way of extending DASH and HLS without using CMAF. Jameson explains some techniques such as advertising segments in advance to allow players to pre-request. It also relies on finding the compromise point of encoding inefficiency vs segment length, typically held to be around 2 seconds, to minimise the latency. At this point we start seeing examples of the techniques in manifests and javascript allowing us to understand how this is actually signalled and implemented.
Apple is on its second major revision of LL-HLS which has responded to many of the initial complaints from the community. Whilst it can use HTTP/2 to help push segments out, this caused problems in practice so it can now preload hints, as Jameson explains in order to remove round-trip times from requests. Jameson looks at the other of Apple’s techniques and shows how they look in manifest files.
The final section looks at problems in implementing these features such as chunks being fragmented across TCP packets, the bandwidth estimation question and dealing with playback speed in order to adjust the players position in time – speed-ups and slow-downs of 5 to 10% can be possible depending on content.
Views and opinions expressed on this website are those of the author(s) and do not necessarily reflect those of SMPTE or SMPTE Members.
This website is presented for informational purposes only. Any reference to specific companies, products or services does not represent promotion, recommendation, or endorsement by SMPTE