How deep do you want to go to make sure viewers get the absolute best quality streamed video? It’s been common over the past few years not to just choose 7 bitrates for a streamed service and encode everything to those bitrates. Rather to at least vary the bitrate for each video. In this talk we examine why doing this is leaving bitrate savings on the table which, in turn, means bitrate savings for your viewers, faster time-to-play and an overall better experience.
Jan Ozer starts with a look at the evolution of bitrate optimisation. It started with Beamr and, everyone’s favourite, FFmpeg. Both of which re-encode every frame until they get the best quality. FFmpeg’s CRF mode will change the quantizer parameter for each frame to maintain the same quality throughout the whole file, though with a variable bitrate. Beamr would encode each frame repeatedly reducing the bitrate until it got the desired quality. These worked well but missed out on a big trick…
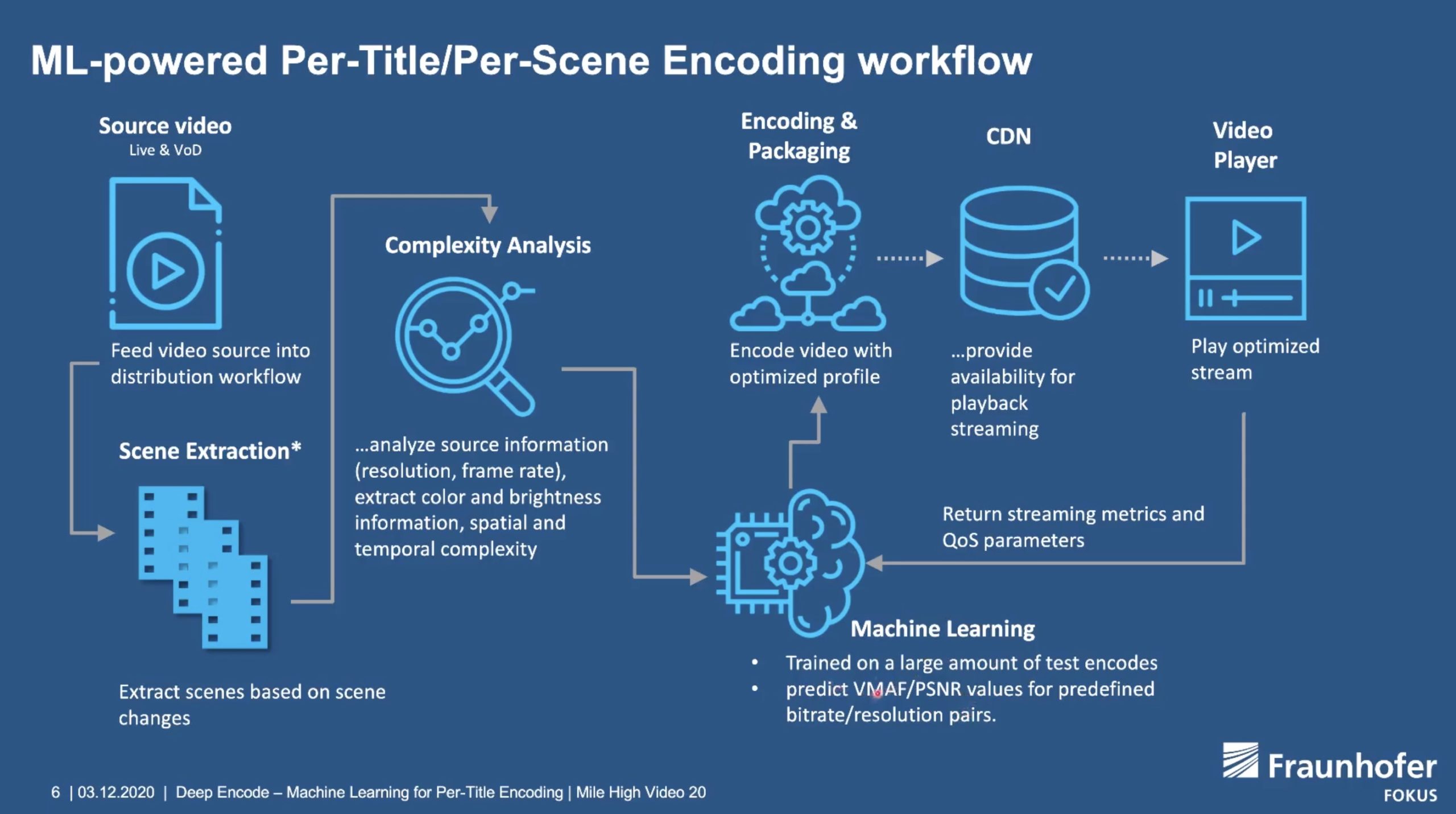
Over the years, it’s been clear that sometimes 720p at 1Mbps looks better than 1080p at 1Mbps. This isn’t always the case and depends on the source footage. Much rolling news will be different from premium sports content in terms of sharpness and temporal content. So, really, the resolution needs to be assessed alongside data rate. This idea was brought into Netflix’s idea of per-title encoding. By re-encoding a title hundreds of times with different resolutions and data rates, they were able to determine the ‘convex hull’ which is a graph showing the optimum balance between quality, bitrate and resolution. That was back in 2015. Moving beyond that, we’ve started to consider more factors.
The next evolution is fairly obvious really, and that’s to make these evaluations not for each video, but for each shot. Doing this, Jan explains, offers bitrate improvements of 28% for AVC and more for other codecs. This is more complex than per-title because the stream itself changes, for instance, GOP sizes, so whilst we know this is something Netflix is using, there are no available commercial implementations currently.
Pushing these ideas further, perhaps the streaming service should take into account the device on which you are viewing. Some TV’s typically only ever take the top two rungs on the ladder, yet many mobile devices have low-resolutions screens and never get around to pulling the higher bitrates. So profiling a device based on either its model or historic activity can allow you to offer different ABR ladders to allow for a better experience.
All of this needs to be enabled by automatic, objective metrics so the metrics need to look out for the right aspects of the video. Jan explains that PSNR and MS-SSIM, though tried and trusted in the industry, only measure spatial information. Jan gives an overview of the alternatives. VMAF, he says, ads a detail loss metric, but it’s not until we start using PW-SSIM from Bright cove where aspects such as device information is taken into account. SSIMPLUS does this and also considers wide colour gamut HDR and frame rates. Similarly ATEME’s ‘Quality Vector’ considers frame rate and HDR.
Dr. Abdul Rehman follows Jan with his introduction to SSIMWAVE’s technologies and focuses on their ability to understand what quality the viewer will see. This allows a provider to choose whether to deliver a quality of ’70’ or, say, ’80’. Each service is different and the demographics will expect different things. It’s important to meet viewer expectations to avoid churn, but it’s in everyone’s interest to keep the data rate as low as possible.
Abdul gives the example of banding which is something that is not easily picked up by many metrics and so can be introduced as the encode optimiser continues to reduce the bitrate oblivious to the obvious banding. He says that since SSIMPLUS is not referenced to a source, this can give an accurate viewer score no matter the source material. Remember that if you use PSNR, you are comparing against your source. If the source is poor, your PSNR score might end up close to the maximum. The trouble is, your viewers will still see the poor video you send them, not caring if this is due to encoding or a bad source.
The video ends with a Q&A.
Watch now!
Speakers
 |
Jan Ozer Principal, Stremaing Learning Center Contributing Editor, Streaming Media |
 |
Abdul Rehman CEO, SSIMMWAVE |