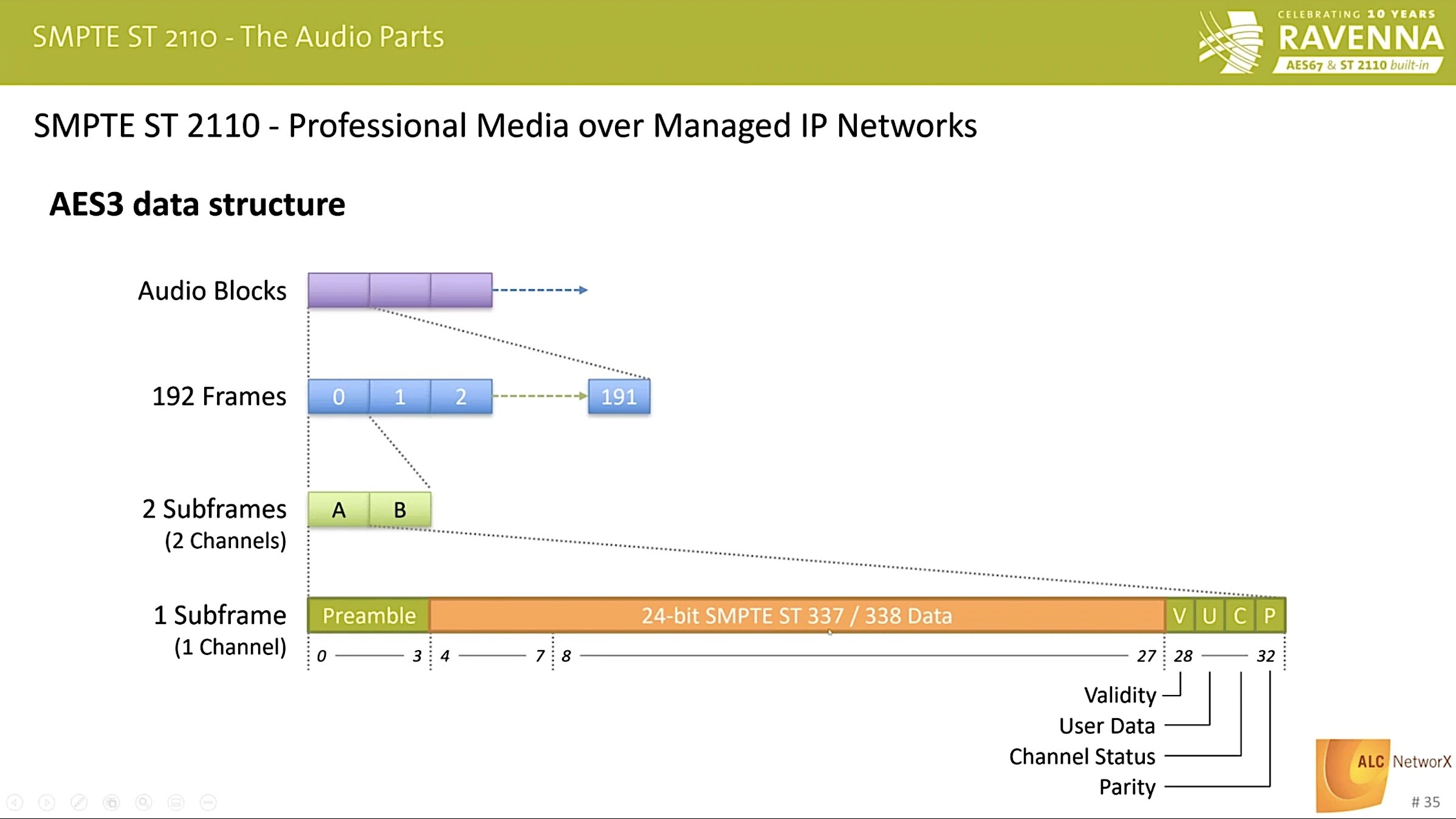
AES67 is a widely adopted standard for moving PCM audio from place to place. Being a standard, it’s ideal for connecting equipment together from different vendors and delivers almost zero latency, lossless audio from place to place. This video looks at use cases for moving AES from its traditional home on a company’s LAN to the WAN.
Discovery’s Eurosport Technology Transformation (ETT) project is a great example of the compelling use case for moving to operations over the WAN. Eurosport’s Olivier Chambin explains that the idea behind the project is to centralise all the processing technology needed for their productions spread across Europe feeding their 60 playout channels.
Control surfaces and some interface equipment is still necessary in the European production offices and commentary points throughout Europe, but the processing is done in two data centres, one in the Netherlands, the other in the UK. This means audio does need to travel between countries over Discovery’s dual MPLS WAN using IGMPv3 multicast with SSM
From a video perspective, the ETT project has adopted 2110 for all essences with NMOS control. Over the WAN, video is sent as JPEG XS but all audio links are 2022-7 2110-30 with well over 10,000 audio streams in total. Timing is done using PTP aware switches with local GNSS-derived PTP with a unicast-over-WAN as a fallback. For more on PTP over WAN have a look at this RTS webinar and this update from Meinberg’s Daniel Boldt.
Bolstering the push for standards such as AES67 is self-confessed ‘audioholic’ Anthony P. Kuzub from Canada’s CBC. Chair of the local AES section he makes the point that broadcast workflows have long used AES standards to ensure vendor interoperability from microphones to analogue connectors, from grounding to MADI (AES10). This is why AES67 is important as it will ensure that the next generation of equipment can also interoperate.
Surrounding these two case studies is a presentation from Nicolas Sturmel all about the AES SC-02-12-M working group which aims to define the best ways of working to enable easy use of AES67 on the WAN. The key issue here is that AES67 was written expecting short links on a private network that you can completely control. Moving to a WAN or the internet with long-distance links on which your bandwidth or choice of protocols is limited can make AES67 perform badly if you don’t follow the best practices.
To start with, Nicolas urges anyone to check they actually need AES67 over the WAN to start with. Only if you need precise timing (for lip-sync for example) with PCM quality and low latencies from 250ms down to as a little as 5 milliseconds do you really need AES67 instead of using other protocols such as ACIP, he explains. The problem being that any ping on the internet, even to something fairly close, can easily take 16 to 40ms for the round trip. This means you’re guaranteed 8ms of delay, but any one packet could be as late as 20ms known as the Packet Delay Variation (PDV).
Not only do we need to find a way to transmit AES67, but also PTP. The Precise Time Protocol has ways of coping for jitter and delay, but these don’t work well on WAN links whether the delay in one direction may be different to the delay for a packet in the other direction. PTP also isn’t built to deal with the higher delay and jitter involved. PTP over WAN can be done and is a way to deliver a service but using a GPS receiver at each location, as Eurosport does, is a much better solution only hampered by cost and one’s ability to see enough of the sky.
The internet can lose packets. Given a few hours, the internet will nearly always lose packets. To get around this problem, Nicolas looks at using FEC whereby you are constantly sending redundant data. FEC can send up to around 25% extra data so that if any is lost, the extra information sent can be leveraged to determine the lost values and reconstruct the stream. Whilst this is a solid approach, computing the FEC adds delay and the extra data being constantly sent adds a fixed uplift on your bandwidth need. For circuits that have very few issues, this can seem wasteful but having a fixed percentage can also be advantageous for circuits where a predictable bitrate is much more important. Nicolas also highlights that RIST, SRT or ST 2022-7 are other methods that can also work well. He talks about these longer in his talk with Andreas Hildrebrand
The video concludes with a Q&A.
Watch now!
Speakers
 |
Nicolas Sturmel Product Manager – Senior Technologist, Merging Technologies |
 |
Anthony P. Kuzub Senior Systems Designer, CBC/Radio Canada |
 |
Olivier Chambin Audio Broadcast Engineer, AioP and Voice-over-IP Eurosport Discovery |